5 Emparejamiento estadístico
Acá va la introducción
5.1 Protocolo de clasificación
El protocolo operativo para clasificar registros como correctos o incorrectos implica tres grandes fases: preprocesamiento de datos, emparejamiento de registros, y evaluación de coincidencias.
5.1.1 Preprocesamiento de datos
Esta fase estandariza y valida la información recolectada, y prepara las bases para el emparejamiento:
- Geocodificación: Consiste en validar que las direcciones estén en los segmentos de la muestra.
- Consistencia Lógica: Busca asegurar que los datos tengan una consistencia desde la lógica de la composición del hogar, edades y relaciones. por ejemplo, verificar que las relaciones de parentesco sean coherentes un hijo/a no puede ser mayor que el jefe de hogar, validar que las edades sean consistentes con las fechas de nacimiento, revisar inconsistencias en la estructura del hogar como que un hogar no puede tener más de un jefe de hogar.
- Normalización de nombres: Se establecen reglas para que los nombres y los apellidos sea válidos. Por ejemplo, que mínimo el primer nombre y primer apellido tengan al menos dos caracteres, eliminar caracteres especiales, espacios innecesarios y normalizar formatos como convertir todo a mayúsculas o minúsculas.
- Estandarización: Consiste en verificar y ajustar los formatos de fechas, sexo, edad y las demás variables que se usarán en el emparejamiento. Por ejemplo, los formatos de fechas deben estar en formato DD/MM/AAAA, unificar categorías de variables categóricas que puedan originar errores (sexo: “M” para masculino, “F” para femenino), revisar y ajustar errores tipográficos o de codificación en variables clave como edad, sexo y relación de parentesco.
- Identificación de duplicados: Detectar registros múltiples del mismo individuo.
- Casos no válidos: Busca identificar individuos ficticios o registros que no corresponden a personas (mascotas, errores de registro, etc).
- Análisis descriptivo: Presentar los resultados del preprocesamiento con el fin de establecer las frecuencias de los valores faltantes. Por ejemplo, porcentaje de registros sin fecha de nacimiento, sin primer nombre, sin segundo nombre, sin departamento, etc.
- Tratamiento de datos faltantes: Imputar datos faltantes o excluir registros no recuperables. Estos corresponden a registros donde no se puede determinar si la enumeración es correcta o incorrecta debido a falta de información. Es importante que exista la evidencia de la decisión, esto se obtiene al marcar los registros con un estado de “imputado” o “excluido”.
5.1.2 Emparejamiento de registros
Esta etapa inicia con la muestra E y muestra P. Si al final del proceso existen registros que no se han logrado emparejar, entonces la muestra E se amplia a otras áreas para identificar si la persona encontrada en la muestra P si fue censada pero en un segmento diferente. A continuación se enuncian las etapas del proceso.
- Determinístico (exacto): Establecer las variables que se usarán para establecer las coincidencias exactas. Es recomendable que el censo y la PES levanten información sobre el tipo de documento y número de documento de identidad, esto ayuda a que el proceso de emparejamiento sea más efectivo.
- Probabilístico: Usar técnicas de vinculación para los registros (record linkage), para los registros que no tuvieron una coincidencia exacta.
- Áreas o bloques de búsqueda: Establecer reglas para limitar el emparejamiento a segmentos censales y áreas adyacentes.
- Definición del umbral: Definir el umbral para establecer las coincidencias es un aspecto relevante, el propósito es minimizar la probabilidad de que un emparejamiento erróneo. En este caso se pueden establecer algunas reglas, si la probabilidad de emparejamiento es superior al 99% se considera “emparejado”, si está entre el 90% y 99% se considera “emparejamiento potencial” y si está por debajo del 90% se considera “no emparejado”.
- Revisión clerical y clasificación: Los registros marcados como “emparejamiento potencial” son revisadas por personal capacitado.
La Figura 5.1 presenta una ilustración general de las fases del proceso de emparejamiento y revisión clerical.
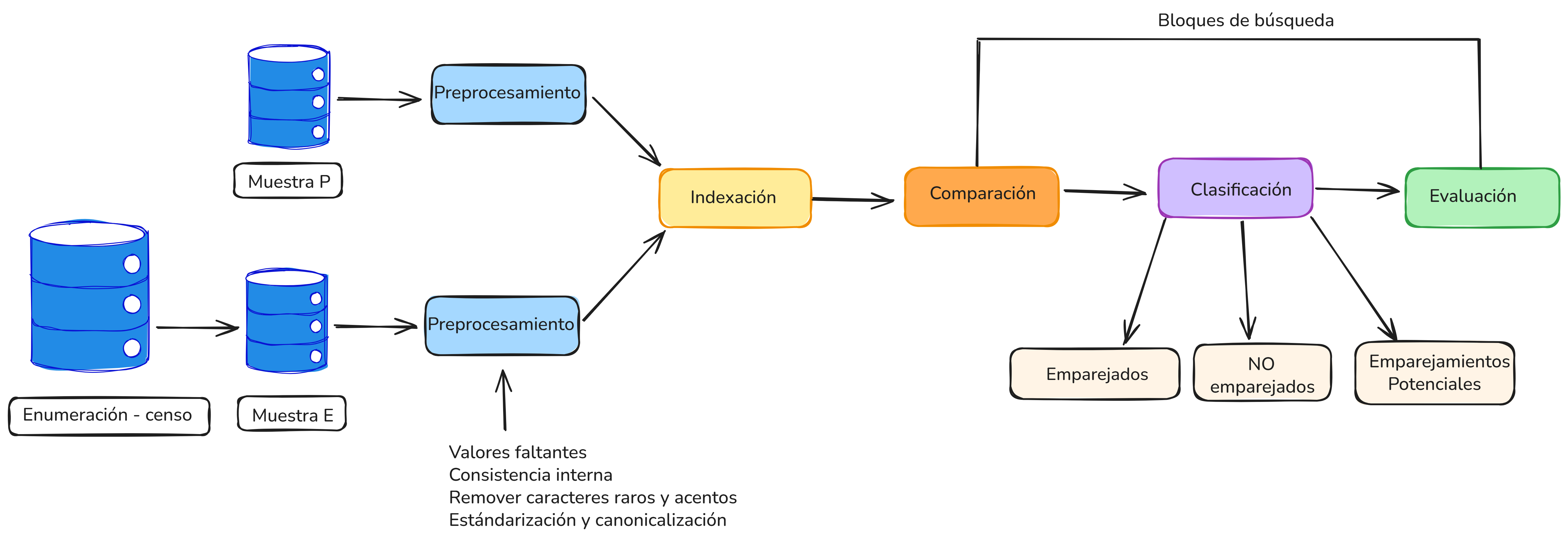
Figure 5.1: Flujo general del proceso de emparejamiento en la PES
Para los registros que tienen estado “no emparejado” se amplia el área de búsqueda hasta llegar al nivel nacional. Como las probabilidades de error de emparejamiento se incrementan cuando se aumenta el área de búsqueda, es recomendable que se haga una revisión clerical de estos registros luego de ser emparejados, incluso si su probabilidad es alta.
Si no hay coincidencia tras ampliar el área de búsqueda, el caso se clasifica como omisión, es decir, personas que no estuvieron enumeradas en el censo. La Figura 5.2 muestra el flujograma que se debría seguir para realizar este proceso.
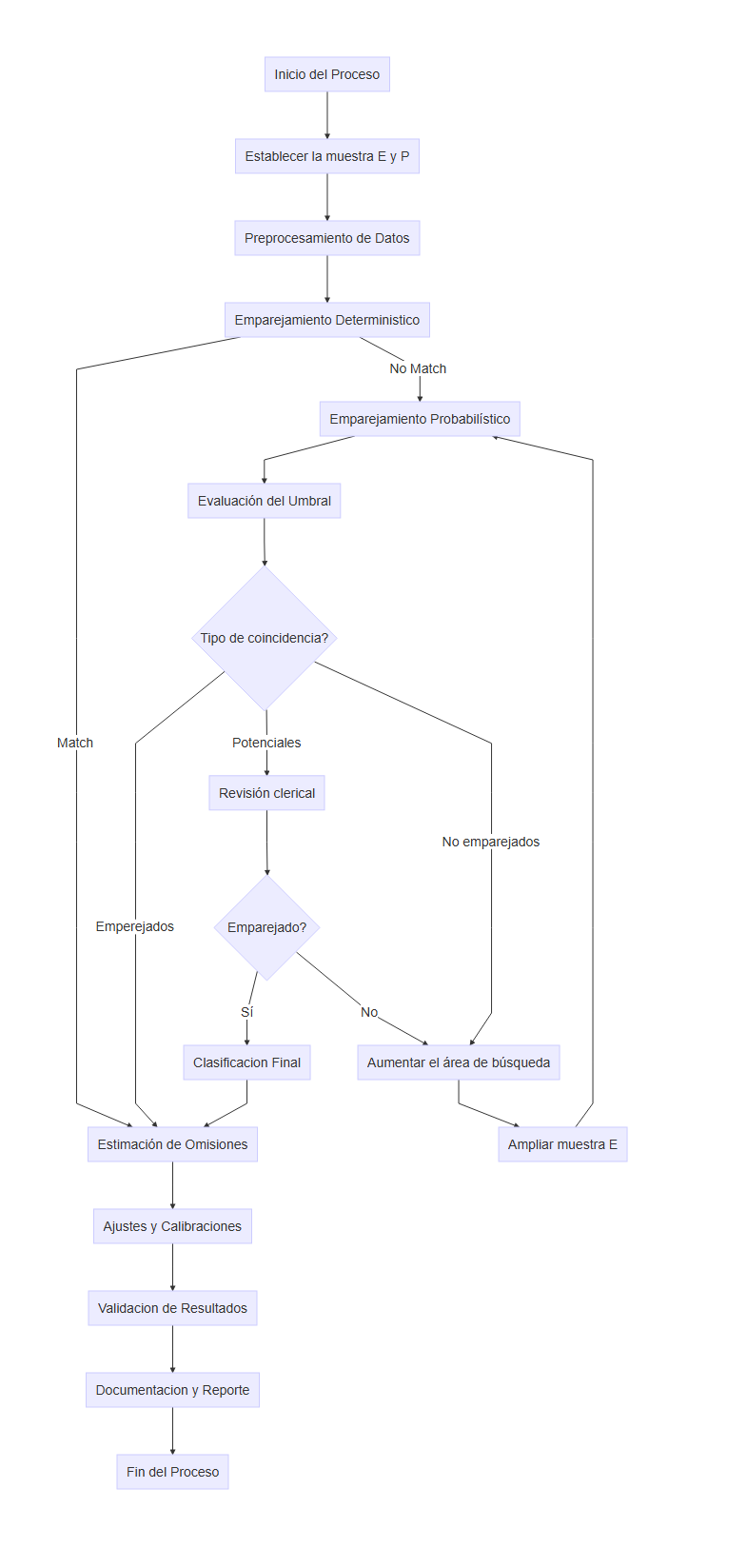
Figure 5.2: Flujo general del proceso de emparejamiento en la PES
5.2 Emparejamiento probabilístico
Las bases de datos censales, rara vez se cuentan con identificadores únicos fiables y completos. Esto hace que el emparejamiento exacto basado en igualdad absoluta de valores en atributos clave, como el número de identificación, sea insuficiente. Además, las variaciones en nombres, errores tipográficos, diferencias de formato y registros incompletos son frecuentes.
Por ejemplo, los registros:
- Nohora Rodriguez, nacida el 8/10/1960
- Nora Rodrigues, nacida el 19601008
pueden referirse a la misma persona, pero un algoritmo exacto no emparejará estos registros. por el contrario, el enfoque probabilístico permite capturar estas coincidencias aproximadas mediante modelos estadísticos, como el propuesto por Fellegi y Sunter (Fellegi and Sunter 1969).
El emparejamiento probabilístico de registros, también conocido como record linkage, tiene una historia extensa en el campo de la estadística y es una técnica fundamental en el contexto de los censos y las encuestas de cobertura. Su objetivo es identificar registros que se refieren a la misma entidad3 entre diferentes fuentes de datos, incluso cuando no se cuenta con un identificador único o cuando los datos contienen errores, inconsistencias o formatos distintos.
La primera vez que se introdujo formalmente el término record linkage fue en el año 1946, para construir un “libro de vida” a nivel de individuo, desde el nacimiento hasta la muerte, incluyendo eventos relevantes como matrimonios, divorcios, registros médicos y de seguridad social (Dunn 1946). Esta visión anticipaba muchos de los principios de lo que hoy se conoce como integración de datos longitudinales, fundamentales para la planificación de servicios públicos y la mejora de la calidad de las estadísticas nacionales.
Durante las décadas de 1950 y 1960, el avance tecnológico permitió que se comenzara con la automatización del proceso de vinculación de registros. Además, se introdujo el enfoque probabilístico, en el cual se asignan pesos de acuerdo con los atributos comparados, considerando la frecuencia relativa de los valores Howard B. Newcombe and Kennedy (1962). Este enfoque sentó las bases para el desarrollo del modelo probabilístico propuesto formalmente por Fellegi y Sunter en 1969, quienes demostraron que bajo ciertas condiciones, es posible derivar una regla óptima para decidir si dos registros corresponden a la misma entidad (Fellegi and Sunter 1969).
A lo largo de las décadas siguientes, este marco teórico fue ampliado por William Winkler en el U.S. Census Bureau, incorporando funciones de comparación aproximada de cadenas, ponderaciones basadas en frecuencia y algoritmos como EM para mejorar la estimación de parámetros del modelo de vinculación probabilística William E. Winkler et al. (2006). En el contexto de los censos de población y vivienda, estas técnicas han sido fundamentales para evaluar la omisión censal mediante encuestas de cobertura, al comparar registros del censo con los de la encuesta y estimar la omisión neta de forma robusta.
La necesidad de vincular datos de múltiples fuentes ha crecido en paralelo con el aumento en la cantidad de información recolectada por Oficinas Nacionales de Estadística (ONE). En este contexto, el emparejamiento de registros cumple múltiples funciones:
- Mejorar la calidad de los datos, al eliminar duplicados y enriquecer registros incompletos.
- Optimizar los costos de operaciones estadísticas al reutilizar datos existentes. Un caso práctico es el Censo Combinado 2023 de Uruguay.
- Viabilizar el análisis longitudinal y de múltiples fuentes, especialmente en contextos censales donde los datos se recolectan en por intervalos de tiempo (Bleiholder and Naumann 2009).
El proceso de emparejamiento consta generalmente de cinco etapas principales:
- Normalización y preprocesamiento: limpieza, estandarización y codificación de atributos.
- Reducción del espacio de búsqueda: indexación o bloques
- Comparación de registros: evaluación de similitudes en atributos comunes (nombre, sexo, fecha de nacimiento, dirección).
- Clasificación: asignación de un estado de emparejado (match), no emparejado (non-match) o revisión clerical (posible match), usualmente mediante reglas probabilísticas (Fellegi and Sunter 1969).
- Predicción final: umbral de clasificación y validación.
El emparejamiento completo entre dos bases con \(n\) y \(m\) registros implica comparar hasta \(n \times m\) pares, lo que resulta en complejidad cuadrática. Para mitigar este costo, se emplean técnicas de indexación conocidas como bloqueo o blocking, que reducen el espacio de comparación considerando solo subconjuntos plausibles de registros.
Una dificultad adicional en el emparejamiento probabilístico es la falta de verdad conocida como ground truth, esto ocurre cuando no se dispone de datos que indiquen con certeza si dos registros corresponden a la misma persona. Esto obliga a realizar revisiones clericales para evaluar la calidad de los emparejamientos. Por esta razón, los procesos logísticos de la encuesta de postcensal (PES) deben considerar una fase de sensibilización para que la población esté dispuesta a colaborar y a entregar información fiable, debido a la resistencia que pueden tener porque fueron censadas hace poco tiempo.
El emparejamiento de registros frecuentemente involucra información sensible como nombres, direcciones y fechas de nacimiento. Por tanto, la privacidad y confidencialidad deben ser cuidadosamente protegidas. En particular, cuando el emparejamiento ocurre entre bases de diferentes entidades, en estos casos se deben aplicar las técnicas de emparejamiento preservando la privacidad (PPRL) (V. Christen et al. 2023; Vatsalan, Karapiperis, and Verykios 2020). Estas consideraciones son especialmente importantes en contextos censales y gubernamentales, donde los datos personales son confidenciales por ley.
5.2.1 Geolocalización
El primer paso consiste en geocodificar las direcciones proporcionadas por los encuestados y verificar que las mismas coinciden con los segmentos cartográficos seleccionados. En caso de que algunas direcciones no tengan una precisión a nivel de segmento cartográfico, entonces será necesaria una revisión clerical para verificar las direcciones proporcionadas por los encuestados.
El siguiente ejemplo, muestra un conjunto de datos con cinco direcciones en distintos municipios d eun país. Cada dirección se combina con el nombre del municipio y el país para formar una dirección completa. Luego, se obtiene la georreferenciación; es decir, las coordenadas de latitud y longitud correspondientes a cada ubicación. La tabla resultante se vería así:
| DIRECCION | MUNICIPIO | LATITUD | LONGITUD |
|---|---|---|---|
| Av. Jaime Mendoza 123 | Sucre | -19.0333 | -65.2622 |
| Calle Bolívar 456 | Monteagudo | -19.7700 | -63.4100 |
| Plaza 25 de Mayo 789 | Camargo | -20.0500 | -64.5500 |
| Av. del Maestro 321 | Villa Serrano | -20.4333 | -64.5500 |
| Calle Potosí 654 | Zudáñez | -19.9000 | -64.8500 |
En caso de que algunos de los puntos de longitud y latitud no queden dentro de los segmentos de la muestra P, los revisores clericales deben verificar las direcciones y establecer si hay descritos algunos puntos de referencia que no se usaron durante el procesamiento automatizado que hubiera afectado la precisión del proceso automático. Los resultados de la geocodificación se utilizan durante el proceso de emparejamiento para identificar áreas de búsqueda alrededor de la dirección proporcionada por el encuestado.
Durante el proceso de geocodificación manual, los revisores asignan una coordenada que permita una mayor precisión. Si no es posible lograr una precisión que apunte a una UPM específica de la muestra P, entonces la misma podrá asociarse a más de una UPM para crear áreas de búsqueda que abarquen dicha dirección. Asimismo, es recomendable que se asigne un código que refleje el nivel de confianza que el revisor manual considera que hay en que la dirección se encuentra dentro del área de búsqueda.
Es recomendable que el emparejamiento automático de personas incluya los geocódigos asignados a las direcciones proporcionadas por los encuestados, así como los nombres, apellidos, la edad, el sexo, el día y mes de nacimiento. Otra información que puede ser usada en el proceso son: los números de teléfono de los encuestados del hogar, datos geográficos como el departamento, municipio o código del segmento. Con este propósito se puede usar un modelo de vinculación probabilística de registros conocido como record linkage.
Con el objetivo de examinar la completitud de los nombres, es recomendable que el nombre o apellido se considere suficiente cuando la combinación del primer y segundo nombre, así como la combinación de los apellidos, tengan al menos dos caracteres cada uno. Posteriormente, los revisores clericales deben analizar todos los registros marcados como insuficientes y actualizar los nombres cuando sea posible. Por ejemplo, puede haberse registrado el primer nombre de un niño pero no su apellido, el revisor clerical podrá completar el apellido basándose en el de los padres cuando el parentesco sea determinado. En estos casos, se podrá cambiar el estado de insuficiente a suficiente.
Al finalizar este procesamiento, cada persona de la muestra P y cada persona de la muestra E deben ser codificadas como coincidencia, posible coincidencia, duplicado, posible duplicado o sin coincidencia, y al finalizar la revisión clerical, se usarán los vínculos asignados a las personas de la muestra P y muestra E como insumos para estimar la cobertura neta de la población y sus componentes.
5.2.2 Flujo general
La Figura 5.3 muestra los pasos principales del proceso de emparejamiento.
- El primer paso es el preprocesamiento de datos, cuyo objetivo es asegurar que los datos de ambas fuentes estén en un formato uniforme y comparable.
- El segundo paso se conoce como indexación, acá se busca reducir la complejidad cuadrática del proceso de emparejamiento mediante el uso de estructuras de datos que permiten generar de manera eficiente y efectiva pares de registros candidatos que probablemente correspondan a la misma persona.
- En el tercer paso, se realiza la comparación de pares de registros, donde los pares candidatos generados a partir de la indexación se comparan utilizando varias variables.
- En el paso de clasificación, los pares de registros se asignan a una de tres categorías: emparejados, no emparejados y emparejamientos potenciales. Si los pares se clasifican como emparejamientos potenciales, se requiere una revisión clerical manual para decidir su estado final (emparejado o no emparejado).
- En el paso final, se evalua la calidad y la completitud de los datos emparejados.
Para la deduplicación de una única base de datos, todos los pasos del proceso de vinculación siguen siendo aplicables. El preprocesamiento es esencial para asegurar que la base completa esté estandarizada, especialmente si los registros han sido ingresados en diferentes momentos, lo que puede haber introducido variaciones en los formatos o en los métodos de captura de datos. La etapa de indexación también es crítica en la deduplicación, ya que comparar cada registro con todos los demás implica un alto costo computacional.
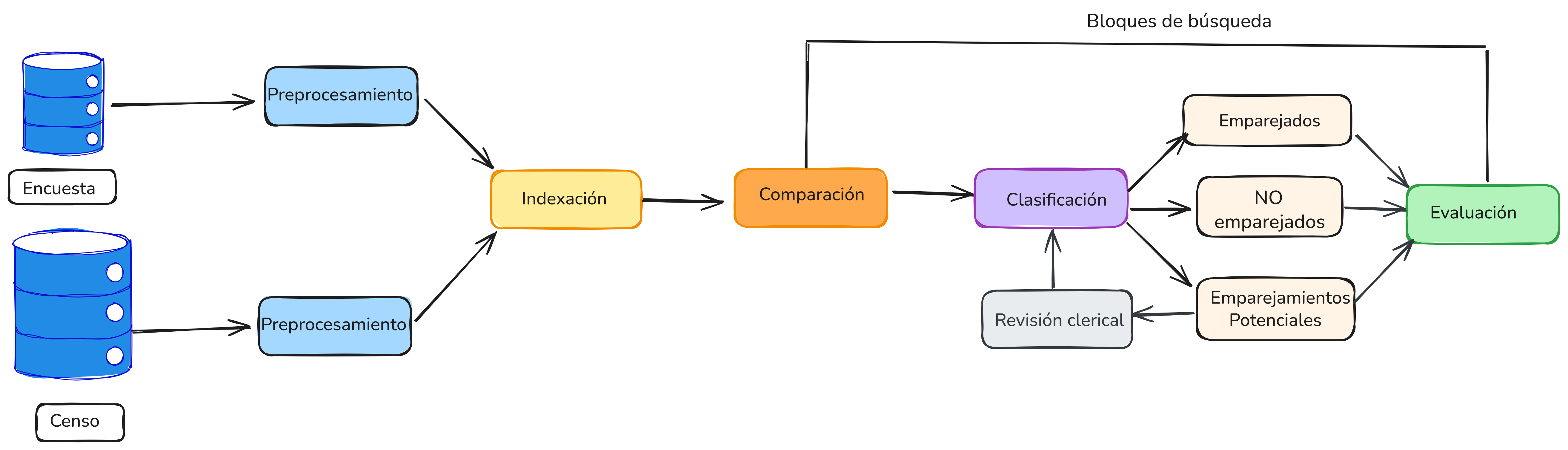
Figure 5.3: Flujo general del proceso de emparejamiento
Para ilustrar las tareas involucradas a lo largo del proceso de emparejamiento de registros, se utilizará un ejemplo compuesto por dos tablas de datos artificiales.
A continuación se presenta la estructura para los primeros registros de la tabla censo:
| Tabla censo | |||||||||
| id_segmento | id_hogar | id_censo | nombre | apellido | sexo | anio_nac | mes_nac | dia_nac | parentesco |
|---|---|---|---|---|---|---|---|---|---|
| 101 | H101_1 | c1 | Carlos | Pérez | M | 1947 | 1 | 1 | Jefe |
| 101 | H101_1 | c2 | Lucía | Castro | F | 1975 | 1 | 1 | Hijo/a |
| 101 | H101_1 | c3 | Camila | Castro | F | 2012 | 1 | 1 | Hijo/a |
| 101 | H101_1 | c4 | María | Castro | F | 1959 | 1 | 1 | Nieto/a |
| 102 | H102_1 | c5 | Jorge | Gómez | M | 1954 | 1 | 1 | Jefe |
| 102 | H102_1 | c6 | Sofía | Ramírez | F | 2000 | 1 | 1 | Hijo/a |
La tabla encuesta presenta la siguiente estructura para los primeros registros:
| Tabla encuesta | ||||||
| id_segmento | id_hogar | id_encuesta | nombre_completo | sexo | fecha_nacimiento | parentesco |
|---|---|---|---|---|---|---|
| 101 | H101_1 | e1 | María Castro | F | 1959-1-1 | Nieto/a |
| 101 | H101_1 | e2 | Carlos Pérez | M | 1947-1-1 | Jefe |
| 101 | H101_1 | e3 | Lucía Castro | F | 1975-1-1 | Hijo/a |
| 101 | H101_10 | e4 | Camila Ramírez | F | 2010-1-1 | Hijo/a |
| 101 | H101_2 | e5 | Sofíá Cástro | F | 1966-1-1 | Jefe |
| 101 | H101_2 | e6 | Ana Martínez | F | 1973-1-1 | Cónyuge |
El objetivo es realizar un proceso de emparejamiento de las dos tablas anteriores. Como puede observarse, aunque ambas contienen información sobre nombre, apellido, sexo, fecha de nacimiento, parentesco y barrio, la estructura de las dos tablas es diferente, al igual que el formato de los valores almacenados en algunas de ellas.
5.2.3 Preprocesamiento
Es común que las tablas de datos que se usarán en el proceso de emparejamiento de datos puedan variar en formato, estructura y contenido. Dado que el emparejamiento de datos comúnmente se basa en información personal, como nombres, sexo, direcciones y fechas de nacimiento, es importante asegurarse de que los datos provenientes de diferentes bases de datos sean limpiados y estandarizados adecuadamente.
El objetivo de esta etapa es garantizar que los atributos utilizados para el emparejamiento tengan la misma estructura y que su contenido siga los mismos formatos. Se ha reconocido que la limpieza y estandarización de datos son pasos cruciales para un emparejamiento exitoso (Herzog, Scheuren, and Winkler 2007). Los datos brutos de entrada deben convertirse en formatos bien definidos y consistentes, y las inconsistencias en la forma en que se representa y codifica la información deben resolverse (Churches et al. 2002).
Existen al menos cinco pasos que son necesarios (aunque probablemente no suficientes) en el preprocesamiento de datos:
Eliminar caracteres y palabras irrelevantes: Este paso corresponde a una limpieza inicial, donde se eliminan caracteres como comas, dos puntos, puntos y comas, puntos, numerales y comillas. En ciertas aplicaciones, también se pueden eliminar algunas palabras si se sabe que no contienen información relevante para el proceso de emparejamiento. Estas palabras también se conocen como “stop words” o palabras vacías.
Expandir abreviaturas y corregir errores ortográficos: Este segundo paso del preprocesamiento es crucial para mejorar la calidad de los datos a emparejar. Comúnmente, este paso se basa en tablas de búsqueda que contienen variaciones de nombres, apodos, errores ortográficos comunes y sus versiones correctas o expandidas. La estandarización de valores realizada en este paso reducirá significativamente las variaciones en atributos que contienen nombres.
Codificación fonética: Es muy común que se tengan errores de ortografía o que los nombres se escriban de manera diferente, por ejemplo “Catalina Benavides” puede corresponder a “Katalina Venavidez”, pero un algoritmo no encontrará la coincidencia perfecta, así que lograr el emparejamiento automático se convierte en un desafío.
Segmentación: Dividir el contenido de atributos que contienen varias piezas de información en un conjunto de nuevos atributos, cada uno con una pieza de información bien definida regularmente es exitoso. El proceso de segmentar valores de atributos también se llama parsing (Herzog, Scheuren, and Winkler 2007). Es de gran importancia realizarlo para nombres, direcciones o fechas. Se han desarrollado diversas técnicas para lograr esta segmentación, ya sea utilizando sistemas basados en reglas o técnicas probabilísticas como modelos ocultos de Markov (Churches et al. 2002).
Verificar: Este paso puede aplicarse cuando existen fuentes externas que permiten realizar una validación de los datos, por ejemplo, si se dispone de una base de datos externa que contenga todas las direcciones conocidas y válidas en un país o región. La información detallada en dicha base de datos debe incluir el rango de números de calles, así como combinaciones de nombres de calles para validar la información del censo y de la PES.
5.2.3.1 Limpieza de los datos
Es posible implementar una rutina de limpieza que limpie y estandarice un texto para que sea más fácil de analizar. A continuación se ejemplifican los pasos para esta limpieza:
- En primer lugar, se debe asegurar que el texto esté en una codificación estándar, lo cual evita que aparezcan símbolos extraños; por ejemplo, un nombre como “José” se convierte correctamente en “José”.
- Luego se transforman todas las letras a minúsculas para uniformar el estilo, de modo que nombres como “Andrés”, “ANDRÉS” y “andrés” queden todos representados como “andrés”.
- Después elimina los acentos y signos diacríticos, de manera que “José” se convierte en “jose” y “María” en “maria”.
- El siguiente paso reemplaza todos los signos de puntuación por espacios; así, un nombre escrito como “Juan-Camilo!” se transforma en “juan camilo”.
- Posteriormente, se reducen los espacios múltiples a un solo espacio, de modo que “Luis Fernando” se corrige a “luis fernando”.
- Finalmente, se eliminan los espacios sobrantes al inicio y al final del texto, de manera que “ Catalina Gómez ” queda como “catalina gomez”.
Como resultado, se obtiene un texto limpio y homogéneo, listo para análisis posterior o procesamiento automático de datos.
De igual manera, el investigador puede definir un conjunto de palabras que considera vacías o irrelevantes para el análisis y que prefiere eliminar de las cadenas de texto. Estas palabras suelen ser artículos, preposiciones o conjunciones que no aportan información significativa, como “de”, “del”, “la”, “los”, “las”, “el” o “y”. Una vez definido este conjunto de palabras, se procede a recorrer el texto y eliminar todas las ocurrencias de estas palabras, asegurándose de que no queden espacios sobrantes ni múltiples espacios consecutivos. Finalmente, se recortan los espacios al inicio y al final de cada texto, de modo que el resultado sea una cadena limpia, homogénea y lista para un análisis más preciso.
Ahora podemos aplicar nuestras funciones sobre las variables de interés en los conjuntos de datos. Es importante destacar que el proceso de preprocesamiento de datos no debe sobrescribir los datos originales y en su lugar, se deben crear nuevos atributos que contengan los datos limpios y estandarizados, o generar nuevas tablas de datos que contengan los datos limpios y estandarizados.
| Tabla censo_limpio | |||||||||
| id_segmento | id_hogar | id_censo | nombre | apellido | sexo | anio_nac | mes_nac | dia_nac | parentesco |
|---|---|---|---|---|---|---|---|---|---|
| 101 | H101_1 | c1 | carlos | perez | m | 1947 | 1 | 1 | jefe |
| 101 | H101_1 | c2 | lucia | castro | f | 1975 | 1 | 1 | hijo a |
| 101 | H101_1 | c3 | camila | castro | f | 2012 | 1 | 1 | hijo a |
| 101 | H101_1 | c4 | maria | castro | f | 1959 | 1 | 1 | nieto a |
| 102 | H102_1 | c5 | jorge | gomez | m | 1954 | 1 | 1 | jefe |
| 102 | H102_1 | c6 | sofia | ramirez | f | 2000 | 1 | 1 | hijo a |
En el caso de la tabla de la encuesta, primero se separa el nombre_completo en varias variables para generar la misma estructura que la tabla del censo, o podría unirse las variables del censo para generar un nombre_unico, lo importante es dejar las tablas en la misma estructura. De igual forma para la fecha de nacimiento. Paso seguido se aplican las funciones sobre las variables de interés.
| Tabla encuesta_limpia | |||||||||
| id_segmento | id_hogar | id_encuesta | nombre | apellido | sexo | anio_nac | mes_nac | dia_nac | parentesco |
|---|---|---|---|---|---|---|---|---|---|
| 101 | H101_1 | e1 | maria | castro | f | 1959 | 1 | 1 | nieto a |
| 101 | H101_1 | e2 | carlos | perez | m | 1947 | 1 | 1 | jefe |
| 101 | H101_1 | e3 | lucia | castro | f | 1975 | 1 | 1 | hijo a |
| 101 | H101_10 | e4 | camila | ramirez | f | 2010 | 1 | 1 | hijo a |
| 101 | H101_2 | e5 | sofia | castro | f | 1966 | 1 | 1 | jefe |
| 101 | H101_2 | e6 | ana | martinez | f | 1973 | 1 | 1 | conyuge |
Las versiones preprocesadas (limpiadas y estandarizadas) de las dos tablas de datos ahora tienen los mismos atributos. El formato y contenido de estos atributos han sido estandarizados.
5.2.3.2 Codificación fonética
Existen diversas funciones diseñadas para codificar fonéticamente los valores de ciertos atributos antes de utilizarlos en procesos de emparejamiento o deduplicación de registros. Su propósito es mitigar los errores derivados de variaciones en la escritura o errores ortográficos, especialmente en variables como nombres, apellidos u otras susceptibles a inconsistencias tipográficas. Estas funciones buscan agrupar cadenas de texto que suenan de forma similar al ser pronunciadas, aunque estén escritas de manera distinta.
La codificación fonética también puede combinarse con medidas de similitud como la distancia de Levenshtein, Smith-Waterman o el coeficiente de Jaccard, para comparar cadenas de texto que suenan de forma similar (Navarro 2001; Nauman and Herschel 2022).
El principio fundamental consiste en transformar un texto en un código fonético basado en su pronunciación. ESin embargo, muchas de las técnicas clásicas fueron desarrolladas para el idioma inglés, lo que limita su aplicabilidad directa en contextos de América Latina y el Caribe, donde se emplean otros idiomas como el español, portugués, francés o lenguas indígenas.
A pesar de estas limitaciones, algunos métodos pueden resultar útiles en este contexto. Por ejemplo, el algoritmo Double Metaphone permite generar codificaciones alternativas para un mismo nombre, considerando distintas variantes ortográficas. Su uso puede mejorar la identificación de coincidencias en registros provenientes de censos y encuestas, donde la calidad y la estandarización de los nombres pueden variar significativamente entre fuentes y regiones.
5.2.3.2.1 Algoritmo Soundex
El algoritmo Soundex es uno de los métodos más antiguos y ampliamente conocidos para la codificación fonética de cadenas de texto. Fue desarrollado originalmente por (Odell and Russell 1918) y ha sido utilizado tradicionalmente en tareas como la consolidación de listas de nombres y la indexación de registros. En el ámbito del emparejamiento de registros entre censos y encuestas de cobertura en América Latina y el Caribe, Soundex puede servir como una herramienta complementaria para enfrentar errores de escritura, diferencias dialectales, y variaciones ortográficas en nombres y apellidos.
Soundex fue diseñado originalmente para nombres en inglés estadounidense, por lo que puede presentar limitaciones en su aplicación directa a nombres hispanos, portugueses o de otras lenguas de la región. Sin embargo, su simplicidad y bajo costo computacional lo convierten en un buen punto de partida para ilustrar los principios básicos de codificación fonética.
| Letras | Código |
|---|---|
| b, f, p, v | 1 |
| c, g, j, k, q, s, x, z | 2 |
| d, t | 3 |
| l | 4 |
| m, n | 5 |
| r | 6 |
| a, e, i, o, u, h, w, y | 0 (se elimina) |
Después de convertir la cadena en dígitos, se eliminan todos los ceros (que corresponden a vocales y las letras ‘h’, ‘w’ e ‘y’), así como las repeticiones del mismo número. Por ejemplo:
Las reglas del algoritmo son:
- Conservar la primera letra del nombre.
- Convertir las letras restantes en números usando la tabla de codificación.
- Eliminar los ceros, ya que las vocales y ciertas consonantes no aportan a la diferenciación fonética.
- Eliminar repeticiones consecutivas del mismo número (por ejemplo, “bb” se convierte en “b1”, no en “b11”).
- Si el código resultante tiene más de tres dígitos, se trunca para que tenga una longitud final de cuatro caracteres (letra + tres dígitos).
- Si tiene menos de tres dígitos, se rellena con ceros.
Este algoritmo se puede implementar en R con el paquete phonics (Howard et al. 2020). La siguiente tabla presenta un ejemplo de codificación con el algoritmo soundex. Se observa que, a pesar de que algunos nombres suenan igual, el algoritmo los diferencia según la primera letra.
| Nombre | Codificación | Resultado Final |
|---|---|---|
| Catalina | C, 0, 3, 4, 0, 4, 5, 0 | C345 |
| Katalina | K, 0, 3, 4, 0, 4, 5, 0 | K345 |
| Yovana | Y, 0, 1, 5, 0, 0 | Y150 |
| Jovanna | J, 0, 1, 5, 5, 0, 0 | J150 |
| Giovanna | G, 0, 1, 5, 5, 0, 0 | G150 |
| Yenny | Y, 0, 5, 5, 0 | Y550 → Y500 |
| Yeni | Y, 0, 5, 0 | Y50 → Y500 |
| Gonzales | G, 0, 5, 2, 4, 2 | G524 |
| Gonzalez | G, 0, 5, 2, 4, 2 | G524 |
## Catalina Katalina Yovana Jovanna Giovanna Yenny Yeni Gonzalez
## "C345" "K345" "Y150" "J150" "G150" "Y500" "Y500" "G524"
## Gonzales
## "G524"5.2.3.2.2 Metaphone
El algoritmo Metaphone es una técnica de codificación fonética desarrollada por Lawrence Philips en 1990 (Philips 1990), diseñada para mejorar la coincidencia de palabras con escritura diferente pero pronunciación similar. A diferencia de algoritmos como Soundex, Metaphone no se limita al análisis de nombres en inglés, lo que lo convierte en una alternativa útil para la deduplicación de datos en contextos de otros idiomas, como los encontrados en los censos y encuestas de cobertura en América Latina y el Caribe.
Una ventaja clave de Metaphone es que no asigna códigos numéricos sino representaciones fonéticas alfabéticas, lo que permite una mayor precisión fonética, especialmente para consonantes. El algoritmo captura 16 sonidos consonánticos comunes en múltiples idiomas y los representa en la transcripción resultante.
No obstante, como fue diseñado originalmente para el inglés, su aplicación en nombres de origen hispano o indígena puede ser limitada. Para superar estas limitaciones, se desarrollaron algoritmos posteriores como Double Metaphone, que permite hasta dos codificaciones por palabra para capturar variaciones fonéticas adicionales, especialmente útiles en bases de datos que tienen varios idiomas (P. Christen 2012).
El algoritmo se puede implementar en R con el paquete phonics de la siguiente manera:
## Catalina Katalina Yovana Jovanna Giovanna Yenny Yeni Gonzalez
## "KTLN" "KTLN" "YFN" "JFN" "JFN" "YN" "YN" "KNSLS"
## Gonzales
## "KNSLS"Note que este algoritmo resulta más preciso para los nombres y apellidos de nuestro ejemplo, generando la misma codificación para los nombres que suenan igual.
5.2.3.2.3 Algoritmo Statistics Canada
El algoritmo fonético desarrollado por Statistics Canada, también conocido como el método de Lynch y Arends (Lynch, Arends, et al. 1977), es una alternativa simple y eficiente para la codificación fonética de nombres, ampliamente utilizada en censos y procesos de vinculación de registros administrativos en Canadá.
Este método es útil cuando se requiere una solución rápida, pero con capacidad de captura de errores comunes de transcripción y ortografía. Es especialmente relevante en contextos de censos de población y encuestas de gran escala en países de América Latina y el Caribe, donde los nombres pueden tener múltiples variantes fonéticas y ortográficas debido a la diversidad cultural.
Entre las características principales del algoritmo se encuentran:
- Elimina las vocales, conservando únicamente la estructura consonántica de los nombres.
- Reduce sonidos duplicados, unificando repeticiones que suelen aparecer por errores de tipeo o escritura fonética.
- No recodifica letras individuales, lo que disminuye la carga computacional.
- Proporciona una forma simplificada de agrupación fonética que no depende del idioma, a diferencia de algoritmos como Soundex o Metaphone.
## Catalina Katalina Yovana Jovanna Giovanna Yenny Yeni Gonzalez
## "CTLN" "KTLN" "YVN" "JVN" "GVN" "YN" "YN" "GNZL"
## Gonzales
## "GNZL"Hay otras alternativas que pueden ser utilizadas, en Howard et al. (2020) se pueden encontrar otros algoritmos como NYSIIS, Caverphone, Cologne, RogerRoot, Phonex o MRA.
5.2.3.2.4 Adaptación para Encuestas de América Latina
A diferencia de los algoritmos fonéticos clásicos como Soundex, Metaphone y StatCan, que fueron desarrollados principalmente para nombres de origen anglosajón, en América Latina los nombres presentan una gran diversidad fonética y ortográfica influenciada por lenguas indígenas, castellano, portugués y otras tradiciones europeas. Por ello, se ha desarrollado un algoritmo personalizado que tiene en cuenta las transformaciones fonéticas y ortográficas más comunes en la región.
La función codif_fonetico() fue diseñada por los autores de este material para capturar las variantes más frecuentes en los nombres latinoamericanos, mediante las siguientes transformaciones:
- Reducción de dobles letras y sílabas características: ll → y, qu → k, ch → x.
- Conversión de combinaciones como ce, ci a se, si; y gue, gui a gi.
- Reglas específicas como ^j → y, ^hua → wa, y ^hu → w, comunes en nombres quechuas o aimaras.
- Normalización de acentos, letra ñ y otros caracteres mediante stri_trans_general(…, “Latin-ASCII”).
- Eliminación de vocales y letras mudas para capturar la estructura fonética esencial.
- Conversión de v a b, y de z a s, fonéticamente indistinguibles en la mayoría de los dialectos del español latino.
El orden en que se aplican las transformaciones también juega un rol especial, el usuario puede ampliar las reglas si así lo desea, incorporando nuevas líneas.
A continuación se presenta la aplicación para nuestro ejemplo
| nombre | codif |
|---|---|
| catalina | KTLN |
| katalina | KTLN |
| yovana | YBN |
| jovanna | YBN |
| giovanna | YBN |
| yenny | YN |
| yeni | YN |
| gonzalez | GNSLS |
| gonzales | GNSLS |
Considere otro ejemplo. La siguiente tabla presenta el resultado de aplicar los algoritmos fonéticos al campo del nombre. En este caso, se puede observar que el método propuesto, columna nom_latino, origina un mejor resultado que los otros algoritmos.
| nombre | apellido | soundex | metaphone | statcan | latino |
|---|---|---|---|---|---|
| Wilmer | Huanca | W456 | WLMR | WLMR | WLMR |
| Guilmer | Wuanca | G456 | KLMR | GLMR | GLMR |
| Wilmar | Guanca | W456 | WLMR | WLMR | WLMR |
| Yohana | Kuispe | Y500 | YHN | YHN | YN |
| Johanna | Quispe | J500 | JHN | JHN | YN |
| Bryan | Kispe | B650 | BRYN | BRN | BRYN |
| Brayan | Qhispe | B650 | BRYN | BRN | BRYN |
| Marleni | Rodriguez | M645 | MRLN | MRLN | MRLN |
| Marleny | Rodrigues | M645 | MRLN | MRLN | MRLN |
| Marlenni | Rodriwues | M645 | MRLN | MRLN | MRLN |
| Nely | Ñahui | N400 | NL | NL | NL |
| Neli | Nahui | N400 | NL | NL | NL |
| Nelly | Nahuy | N400 | NL | NL | NL |
| Ximena | Ñawi | X550 | SMN | XMN | YMN |
| Jimena | Ñahui | J550 | JMN | JMN | YMN |
En el caso del apellido, es fundamental tener en cuenta las particularidades culturales de cada región, ya que pueden influir significativamente en la forma en que son escritos o pronunciados. Estas variaciones hacen que ningún algoritmo de codificación fonética sea completamente robusto por sí solo, por lo que es recomendable adaptar o complementar los métodos según el contexto local.
| nombre | apellido | soundex | metaphone | statcan | latino |
|---|---|---|---|---|---|
| Wilmer | Huanca | H520 | HNK | HNC | WNK |
| Guilmer | Wuanca | W520 | WNK | WNC | WNK |
| Wilmar | Guanca | G520 | KNK | GNC | GNK |
| Yohana | Kuispe | K210 | KSP | KSP | KSP |
| Johanna | Quispe | Q210 | KSP | QSP | KSP |
| Bryan | Kispe | K210 | KSP | KSP | KSP |
| Brayan | Qhispe | Q210 | KHSP | QHSP | KSP |
| Marleni | Rodriguez | R362 | RTRKS | RDRG | RDRGS |
| Marleny | Rodrigues | R362 | RTRKS | RDRG | RDRGS |
| Marlenni | Rodriwues | R362 | RTRWS | RDRW | RDRWS |
| Nely | Ñahui | N000 | NH | NH | NW |
| Neli | Nahui | N000 | NH | NH | NW |
| Nelly | Nahuy | N000 | NH | NH | NW |
| Ximena | Ñawi | N000 | NW | NW | NW |
| Jimena | Ñahui | N000 | NH | NH | NW |
La siguiente tabla muestra el resultado de aplicar la función codif_fonetico tanto al nombre como al apellido. No obstante, se recomienda utilizar en cada campo el algoritmo fonético que mejor se adapte a las características lingüísticas y culturales del caso específico.
| nombre | apellido | nom_cod | ape_cod |
|---|---|---|---|
| Wilmer | Huanca | WLMR | WNK |
| Guilmer | Wuanca | GLMR | WNK |
| Wilmar | Guanca | WLMR | GNK |
| Yohana | Kuispe | YN | KSP |
| Johanna | Quispe | YN | KSP |
| Bryan | Kispe | BRYN | KSP |
| Brayan | Qhispe | BRYN | KSP |
| Marleni | Rodriguez | MRLN | RDRGS |
| Marleny | Rodrigues | MRLN | RDRGS |
| Marlenni | Rodriwues | MRLN | RDRWS |
| Nely | Ñahui | NL | NW |
| Neli | Nahui | NL | NW |
| Nelly | Nahuy | NL | NW |
| Ximena | Ñawi | YMN | NW |
| Jimena | Ñahui | YMN | NW |
Ahora aplicaremos la función codif_fonetico a nuestros conjuntos de datos del censo y de la encuesta
5.2.4 Indexación
Las tablas de datos limpias y estandarizadas están listas para ser emparejadas. Inicialmente, cada registro de la tabla del censo necesita compararse con todos los registros de la tabla de la encuesta. Esto conduce a un número total de comparaciones de pares de registros que es cuadrático respecto al tamaño de las tablas de datos a emparejar. Por ejemplo, en nuestro ejercicio la tabla del censo tiene 97 registros y la tabla de la encuesta tiene 54 registros, así que sería necesario un total de 5238 comparaciones.
Por supuesto, esta comparación ingenua de todos los pares de registros no es escalable para datos muy grandes. Por ejemplo, el censo de Colombia en el año 2018 tuvo una enumeración de más de 44 millones de personas y usó una PES de 283 mil personas, lo que originaría más de 12 billones de comparaciones de pares de registros. Incluso si se pudieran realizar 100 mil comparaciones por segundo, el proceso de comparación tomaría más de 33 mil horas, más de mil días, que equivale a casi 4 años.
Por lo anterior es necesario realizar una optimización del proceso usando técnicas de indexación (blocking) combinado con un proceso de procesamiento en paralelo y de ser posible sistemas distribuidos (como Apache Spark).
En las muestras de cobertura se usan segmentos muestrales equivalentes a los del censo, es decir, el código del segmento se refiere a la misma área geográfica, y en consecuencia es más probable que una persona que vive en el segmento 1 de la muestra de cobertura, también se encuentre en el segmento 1 del censo; así que comparar los pares de registros dentro del mismo segmento será la primera alternativa. Sin embargo, cuando el tiempo entre el censo y la PES empieza a ser mayor, la probabilidad de que las personas se encuentren en el mismo segmento se reduce, esto debido a que las familias se pueden mudar y en ese caso el enfoque de bloqueo pierde el par porque están en segmentos diferentes, esto también ocurre con los moovers o personas que el día del censo no están en su lugar de residencia habitual. Otros ejemplos más complejos pueden darse cuando una mujer se ha casado y cambia su apellido y dirección, y por lo tanto no es detectada por los criterios de bloqueo y tampoco se detectaría en la comparación completa.
En este sentido, del censo se extrae la muestra de enumeración (muestra E) que corresponde a todos los hogares que están en los mismos segmentos de la PES (muestra P), y de esta forma iniciar el proceso de emparejamiento con estos dos conjuntos de datos.
Sea \(n_0\) el tamaño de la muestra de la PES, \(N_{+1}\) la cantidad de personas enumeradas en el censo y \(n_E\) la cantidad de personas enumeradas en la muestra E. Los pasos de la indexación son:
- Realizar el emparejamiento entre la muestra E y la muestra P. Suponga que \(C^{(1)}\) es el conjunto de personas emparejadas en este paso, donde \(n_1<n_0\) es la cantidad de personas emparejadas, entonces \(P^{(1)}\) es el conjunto de personas de la muestra P que no fueron emparejadas y \(m_1 = n_0 - n_1\) es la cantidad de personas que no fueron emparejadas en este paso.
- Sea \(M^{(2)}\) la muestra de segmentos en un área más grande alrededor de cada segmento de la muestra \(P\), esto para generar los nuevos bloques de indexación, es decir, si el segmento de la muestra \(P\) es una manzana cartográfica entonces el bloque podría ampliarse a una sección cartográfica o barrio para generar una búsqueda en un área mayor pero sin que se desborde la cantidad de comparaciones.
- Sea \(E_2 = M^{(2)} - C^{(1)}\) la muestra de enumeración en un área más grande luego de retirar los elementos que ya fueron emparejados.
- Realizar el emparejamiento entre la muestra \(E_2\) y la muestra \(P^{(1)}\). Suponga que \(C^{(2)}\) es el conjunto de personas emparejadas en este paso, donde \(n_2<m_1\) es la cantidad de personas emparejadas, entonces \(P^{(2)}\) es el conjunto de personas de la muestra \(P^{(1)}\) que no fueron emparejadas y \(m_2 = m_1 - n_2\) es la cantidad de personas que no fueron emparejadas en este paso.
- Sea \(M^{(3)}\) la muestra de segmentos en un área más grande alrededor de cada bloque usado en \(M^{(2)}\), es decir, si en el paso anterior el bloque se amplió a una sección cartográfica entonces ahora se puede ampliar a un sector censal o si era el barrio entonces ampliarlo a una zona catastral más grande, y así generar una búsqueda en un área mayor pero sin que se desborde la cantidad de comparaciones.
- Sea \(E_3 = M^{(3)} - \bigcup_{i=1}^2C^{(i)}\) la muestra de enumeración en un área más grande luego de retirar los elementos que ya fueron emparejados.
- Realizar el emparejamiento entre la muestra \(E_3\) y la muestra \(P^{(2)}\). Ahora \(C^{(3)}\) es el conjunto de personas emparejadas en este paso, donde \(n_3<m_2\) es la cantidad de personas emparejadas, entonces \(P^{(3)}\) es el conjunto de personas de la muestra \(P^{(2)}\) que no fueron emparejadas y \(m_3 = m_2 - n_3\) es la cantidad de personas que no fueron emparejadas en este paso.
- Continuar el procedimiento hasta que \(M^{(j)}\) sea igual al censo o hasta que \(m_j=0\), es decir, que no hay elementos sin emparejar.
5.2.5 Comparación
Existen varios métodos para la comparación de cadenas y otros tipos de variables en procesos de emparejamiento de registros. A continuación se describen algunas de las métricas que son más utilizadas, sus fundamentos matemáticos, ventajas, limitaciones y posibles aplicaciones en contextos como nombres de personas, direcciones, fechas, ubicaciones geográficas y otros campos relevantes en bases de datos administrativas.
5.2.5.1 Distancia de Levenshtein
La distancia de Levenshtein es una métrica que calcula el número mínimo de operaciones de edición (inserciones, eliminaciones y sustituciones) necesarias para transformar una cadena de texto en otra. Sea \(s_1\) y \(s_2\) dos cadenas de texto. Se construye una matriz \(d[i,j]\) tal que:
\[d[i, j] = \begin{cases} d[i - 1, j - 1] & \text{si } s_1[i] = s_2[j] \\ \min \begin{cases} d[i - 1, j] + 1 \\ d[i, j - 1] + 1 \\ d[i - 1, j - 1] + 1 \end{cases} & \text{si } s_1[i] \ne s_2[j] \end{cases} \]
La distancia de Levenshtein entre \(s_1\) y \(s_2\) es el valor \(d[|s_1|, |s_2|]\). Puede transformarse en una medida de similitud, así:
\[\text{sim}_{\text{levenshtein}}(s_1, s_2) = 1 - \frac{\text{dist}_{\text{levenshtein}}(s_1, s_2)}{\max(|s_1|, |s_2|)}\]
Esta métrica es simétrica con respecto a \(s_1\) y \(s_2\), y satisface la propiedad \(|\ |s_1| - |s_2|\ | \le \text{dist}_{\text{levenshtein}}(s_1, s_2)\) (P. Christen 2012).
Ejemplo: Suponga que se tienen las cadenas \(s_1 = \texttt{Laura}\) y \(s_2=\texttt{Lara}\). Transformar “Laura” en “Lara” se debe eliminar la “u”, es decir que solo se requiere una operación, así que la distancia de Levenshtein es 1. Si tenemos en cuenta que las longitudes de las palabras son \(|s_1|=5\) y \(|s_2|=4\), entonces
\[\text{sim}_{\text{levenshtein}}(s_1, s_2) = 1 - \frac{1}{\max(5, 4)}=1-\frac{1}{5}=0.8\]
5.2.5.2 Comparación de Jaro y Winkler
La similitud de Jaro está especialmente diseñada para nombres y toma en cuenta caracteres comunes y transposiciones (P. Christen 2012):
\[\text{sim}_{\text{jaro}}(s_1, s_2) = \frac{1}{3} \left( \frac{c}{|s_1|} + \frac{c}{|s_2|} + \frac{c - t}{c} \right)\]
donde \(c\) es el número de caracteres coincidentes y \(t\) el número de transposiciones. La similitud de Jaro-Winkler ajusta la de Jaro con base en un prefijo común:
\[\text{sim}_{\text{winkler}}(s_1, s_2) = \text{sim}_{\text{jaro}}(s_1, s_2) + p \cdot (1 - \text{sim}_{\text{jaro}}(s_1, s_2)) \cdot 0.1\]
donde \(p\) es el número de caracteres idénticos al inicio (\(0\leq p \leq 4\)).
Ejemplo: Para las cadenas \(s_1 = \texttt{Laura}\) y \(s_2=\texttt{Lara}\) se tienen 3 caracteres coincidentes (L, a, a), \(c=3\). Además, la segunda “a” de “Laura” está en posición 5, mientras que en “Lara” está en posición 4, esto indica que al menos una letra está fuera de lugar con respecto a su par coincidente y esto se cuenta como una transposición, por lo tanto habrá 1 transposición. Jaro considera las transposiciones como el número de caracteres coincidentes que están en diferente orden entre las dos cadenas, dividido por 2, esto es:
\[t = \frac{\text{Número de caracteres fuera de lugar}}{2} = \frac{1}{2}\]
\[\text{sim}_{\text{jaro}}(\text{Laura}, \text{Lara}) = \frac{1}{3}\left( \frac{3}{5} + \frac{3}{4} + \frac{3 - 1/2}{3}\right) \approx 0.728\]
5.2.5.3 Comparación de fechas y edades
Las fechas y edades se comparan de forma directa, considerando:
- Diferencia de días, meses o años.
- Rangos aceptables para considerar coincidencias (por ejemplo, diferencias de 1 año en edad).
- En caso de comparar edad y fecha de nacimiento, se puede validar la coherencia temporal.
Una forma alternativa de comparar fechas es convertirlas en edades y luego calcular la diferencia en términos porcentuales, lo cual permite cierto grado de tolerancia. Para ello, las edades se deben calcular respecto a una fecha fija, que puede ser la fecha del cierre de la PES o la fecha del emparejamiento entre bases de datos o cualquier fecha relevante al contexto.
Supongamos que \(d_1\) y \(d_2\) representan la edad (en días o años) calculada desde la fecha fija. Entonces, la diferencia porcentual de edad (DPE) se calcula como:
\[\text{dpe} = \frac{|d_1 - d_2|}{\max(d_1, d_2)} \cdot 100.\]
Con base en este valor, se puede calcular la similitud porcentual de edad como:
\[ \text{sim}_{\text{edadporc}} = \begin{cases} 1.0 - \frac{\text{dpe}}{\text{dpe}_{\max}}, & \text{si } \text{dpe} < \text{dpe}_{\max} \\ 0.0, & \text{en otro caso} \end{cases} \]
donde \(\text{dpe}_{\max} \in (0, 100)\) representa la diferencia porcentual máxima tolerada (P. Christen 2012).
5.2.5.4 Comparación geográfica
Para campos geográficos como coordenadas o nombres de lugares se puede usar una distancia euclidiana o geodésica. Por ejemplo, la fórmula de Haversine que es utilizada para calcular la distancia entre dos puntos de una esfera dadas sus coordenadas de longitud y latitud. En caso de tener las coordenadas, se define:
\[d = 2r \cdot \arcsin\left( \sqrt{\sin^2\left(\frac{\phi_2 - \phi_1}{2}\right) + \cos(\phi_1) \cos(\phi_2) \sin^2\left(\frac{\lambda_2 - \lambda_1}{2}\right)} \right)\]
donde \(\phi\) es la latitud, \(\lambda\) la longitud y \(r\) el radio de la Tierra. De igual forma, se puede hacer una comparación desde nivel país hasta nivel barrio (matching jerárquico) o usando la codificación administrativa normalizada (DANE, INEGI, etc.).
5.2.6 Clasificación
El enfoque clásico es el modelo probabilístico de Fellegi y Sunter (Fellegi and Sunter 1969), este modelo considera dos conjuntos de registros:
- \(A\): registros provenientes del censo
- \(B\): registros provenientes de la PES
El objetivo es determinar si un par \((a, b) \in A \times B\) representa la misma entidad (es decir, un match) o no.
Se define el universo total de pares posibles como:
\[A \cup B = M \times U\]
En donde:
- \(M\): conjunto de pares que son emparejamientos
- \(U\): conjunto de pares que no son emparejados
Para cada par \((a, b)\) se define una función de comparación:
\[\boldsymbol{\gamma}(a, b) = (\gamma_1, \gamma_2, \dots, \gamma_d) \in \{0,1\}^d\]
En donde \(d\) es el número de atributos comparados (por ejemplo, nombre, sexo, fecha de nacimiento), y cada \(\gamma_j\) indica si hay coincidencia (\(\gamma_j = 1\)) o no (\(\gamma_j = 0\)) en el atributo \(j\).
El modelo asume independencia condicional de las comparaciones dado el estado del emparejamiento (match o non-match). Así, para un vector de comparación específico \(\boldsymbol{g}\), se cumple:
\[P(\boldsymbol{\gamma} = \boldsymbol{g} \mid M) = \prod_{j=1}^d m_j^{g_j} (1 - m_j)^{1 - g_j}\]
y,
\[P(\boldsymbol{\gamma} = \boldsymbol{g} \mid U) = \prod_{j=1}^d u_j^{g_j} (1 - u_j)^{1 - g_j}\]
En donde: - \(m_j = P(\gamma_j = 1 \mid M)\) es la probabilidad de coincidencia en el atributo \(j\) entre pares que son matches - \(u_j = P(\gamma_j = 1 \mid U)\) es la probabilidad de coincidencia en el atributo \(j\) entre pares que no son matches
Estos parámetros pueden estimarse mediante métodos de máxima verosimilitud, como el algoritmo EM o mediante enfoques bayesianos (William E. Winkler 2000; Larsen and Rubin 2001).
Para decidir si un par \((a, b)\) representa la misma entidad, se calcula la razón de verosimilitud (también llamada puntaje de coincidencia o match score):
\[\log L(\boldsymbol{g}) = \log P(\boldsymbol{\gamma} = \boldsymbol{g} \mid M) - \log P(\boldsymbol{\gamma} = \boldsymbol{g} \mid U)\]
Este valor representa la evidencia a favor de que el par \((a, b)\) corresponde a un emparejamiento verdadero. Cuanto mayor sea el valor de \(\log L(\boldsymbol{g})\), mayor será la probabilidad de que los registros representen a la misma persona.
Basándose en los valores del puntaje de coincidencia, se definen dos umbrales:
- Si \(\log L(\boldsymbol{g}) \geq T_M\): se clasifica como emparejado.
- Si \(\log L(\boldsymbol{g}) \leq T_U\): se clasifica como no emparejado.
- Si \(T_U < \log L(\boldsymbol{g}) < T_M\): se clasifica como emparejamiento potencial, sujeto a revisión clerical.
Este enfoque tradicional puede complementarse con modelos de aprendizaje supervisado o no supervisado. En estos casos, los pares de registros se representan como vectores de características derivadas de la comparación y se utilizan reglas de clasificación que buscan maximizar las coincidencias reales, para más detalles se recomienda consultar (P. Christen 2012, Capítulo 6).
5.2.7 Evaluación
Como se ha discutido, las técnicas de clasificación para el emparejamiento de datos buscan maximizar la calidad de los resultados. No obstante, evaluar dicha calidad requiere la existencia de un conjunto de referencia, es decir, un conjunto donde se conozca con certeza si cada par de registros corresponde a la misma entidad o no. Esta información debe reflejar fielmente las características de los datos reales bajo análisis (P. Christen 2012).
En el contexto de censos y encuestas de cobertura, un emparejamiento correcto implica que un registro del censo y uno de la encuesta representan a la misma persona. De manera análoga, un par no emparejado representa dos entidades distintas. La disponibilidad de datos de referencia permite calcular métricas similares a las usadas en modelos de aprendizaje automático para problemas de clasificación binaria (Menestrina, Whang, and Garcia-Molina 2010).
En la práctica, estos conjuntos de referencia rara vez están disponibles de forma directa. Por ello, es necesario implementar procesos de codificación manual, que consisten en realizar un muestreo de la muestra P (emparejada) y realizar la verificación manual en la muestra E (o en el censo) para verificar manualmente su veracidad. Este procedimiento puede ser costoso, especialmente si se aplican esquemas de muestreo estratificado que demanden una cantidad significativa de revisiones.
Dado un conjunto de referencia, los pares de registros se clasifican en las siguientes categorías (P. Christen 2012):
- Verdaderos positivos (VP): pares correctamente emparejados.
- Falsos positivos (FP): pares que fueron emparejados incorrectamente.
- Verdaderos negativos (VN): pares correctamente no emparejados.
- Falsos negativos (FN): pares que no fueron emparejados, pero deberían haberlo sido.
En contextos censales, suele haber un desbalance extremo entre clases. Por esta razón, métricas como la exactitud (accuracy) o la especificidad pueden ser engañosas. Por ejemplo, un clasificador que marque todos los pares como “no emparejados” puede alcanzar una alta exactitud.
5.2.7.1 Métricas de desempeño
Las métricas más informativas en estas operaciones estadísticas son (P. Christen 2012; Nauman and Herschel 2022):
Precisión (Precision): Proporción de emparejamientos correctos entre los clasificados como positivos.
\[prec = \frac{VP}{VP + FP}\]
Exhaustividad (Recall): Proporción de emparejamientos reales detectados.
\[rec = \frac{VP}{VP + FN}\]
Medida-F (F-measure): Media armónica de precisión y exhaustividad.
\[F_1 = 2 \cdot \frac{P \cdot R}{P + R}\]
5.2.7.2 Métricas de eficiencia
Además de la calidad del emparejamiento, se deben evaluar aspectos de eficiencia del proceso:
- Reducción: proporción de pares descartados durante la etapa de indexación o bloqueo.
- Completitud de pares: proporción de emparejamientos verdaderos que fueron efectivamente retenidos después del bloqueo.
- Calidad de pares: proporción de los pares retenidos que son verdaderos emparejamientos.
Estas métricas son útiles para comparar algoritmos de indexación y estrategias de bloqueo.
5.2.8 Revisión clerical
En las operaciones censales, el emparejamiento automático entre la muestra de cobertura y el censo suele ser insuficiente. Por esta razón, es común implementar procesos de revisión manual, conocidas como revisión clerical, que son realizadas por un equipo de expertos, quienes validan los posibles emparejamientos ambiguos o dudosos. La calidad de esta revisión depende de múltiples factores:
- La experiencia y entrenamiento de los revisores.
- La disponibilidad de herramientas que faciliten la comparación contextual de los registros (por ejemplo, mostrando registros similares o agrupando por hogar).
- El acceso a fuentes de información adicionales (como historiales de direcciones, nombres alternativos, o registros administrativos complementarios).
En resumen, la evaluación rigurosa del emparejamiento requiere no solo técnicas automáticas robustas, sino también mecanismos de validación y control de calidad que aseguren su confiabilidad.
5.3 Implementación
A continuación se presenta un resumen de los principales paquetes de R y Python que se pueden utilizar para la vinculación probabilística de registros:
| Lenguaje | Paquete | Características principales |
|---|---|---|
| R | RecordLinkage |
Implementa Fellegi-Sunter, Soundex, Jaro-Winkler, Levenshtein. Permite bloques, clasificación supervisada o no. |
| R | fastLink |
Modelo bayesiano de Fellegi-Sunter. Maneja datos faltantes. Permite estimación de probabilidades y escalabilidad. |
| R | fuzzyjoin |
Permite uniones por coincidencias parciales como stringdist, regex y se integra con dplyr. |
| R | stringdist |
Ofrece múltiples métricas de distancia (Levenshtein, Jaccard, Jaro, Hamming). Útil para comparaciones de texto. |
| Python | recordlinkage |
Implementa Fellegi-Sunter, SVM, Random Forests. Permite bloques y evaluación de desempeño. |
| Python | Dedupe |
Usa aprendizaje supervisado y semi-supervisado. Permite bloques y métodos de clúster. |
| Python | splink |
Basado en Fellegi-Sunter, escalable con Spark, DuckDB o SQL. Visualización interactiva. Soporta paralelización. |
5.3.1 Deduplicación de registros
Una etapa clave en el cálculo de la omisión censal, es asegurar que la base de enumeración de la PES no tiene duplicados. Poder identificar si una persona ha sido enumerada más de una vez en el censo, se conoce como proceso de deduplicación.
Ejemplo usando el paquete RecordLinkage
Para ilustrar este procedimiento se implementará un análisis supervisado utilizando los datos simulados RLdata500 incluidos en el paquete RecordLinkage de R. El conjunto de datos contiene 500 registros simulados, incluyendo nombres, apellidos, fechas de nacimiento y un identificador de la persona real (identity.RLdata500). Suponga que este es un conjunto de entrenamiento que fue seleccionado con unos registros del censo, y en el cual se realizó un proceso de identificación y revisión clerical para identificar con certeza si un registro es duplicado o no, de esta manera es posible entrenar un modelo, realizar evaluaciones de precisión y entender mejor las decisiones del algoritmo.
| fname_c1 | fname_c2 | lname_c1 | lname_c2 | by | bm | bd |
|---|---|---|---|---|---|---|
| CARSTEN | NA | MEIER | NA | 1949 | 7 | 22 |
| GERD | NA | BAUER | NA | 1968 | 7 | 27 |
| ROBERT | NA | HARTMANN | NA | 1930 | 4 | 30 |
| STEFAN | NA | WOLFF | NA | 1957 | 9 | 2 |
| RALF | NA | KRUEGER | NA | 1966 | 1 | 13 |
| JUERGEN | NA | FRANKE | NA | 1929 | 7 | 4 |
En caso de realizar todas la comparaciones por pares, serían necesarias 124.750 comparaciones:
\[\binom{N}{2} = \binom{500}{2} = 124.750\] Lo anterior es manejable en conjuntos de datos pequeños, pero en los casos de censos o encuestas de cobertura no resulta viable aplicar el total de comparaciones, por lo que será necesario realizar una indexación con unos bloques de comparación.
Como se ha mencionado antes, el bloqueo consiste en agrupar los registros en bloques más pequeños usando una o más variables, de manera que solo se comparan registros dentro del mismo bloque. En este ejemplo se usará la primera letra del apellido como clave de bloqueo.
| A | B | D | E | F | G | H | J | K | L | M | N | O | P | R | S | T | V | W | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 56 | 2 | 6 | 38 | 12 | 32 | 8 | 46 | 13 | 76 | 8 | 4 | 6 | 7 | 115 | 2 | 7 | 52 | 5 |
Lo anterior genera 20 bloques, donde el número de registros por bloque puede ser diferente. Como ahora el número de comparaciones se realiza dentro de cada bloque, esto reduce drásticamente el número total de comparaciones que se tienen que realizar. Sin embargo, es recomendable evitar una alta variación en el número de registros por bloque, esto debido a que algunos bloques con un alto número de registros puede incremetar fuertemente el costo computacional. En este caso el número de registros por bloque varía entre 2 y 115.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.00 5.75 8.00 25.00 40.00 115.00A pesar de lo anterior, el número de pares posibles tras aplicar el bloqueo baja de 1.2475^{5} a 1.4805^{4} pares. Esta reducción es crucial para el rendimiento computacional del algoritmo. A continuación se observa el número de comparaciones por bloque.
| A | B | D | E | F | G | H | J | K | L | M | N | O | P | R | S | T | V | W | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 1540 | 1 | 15 | 703 | 66 | 496 | 28 | 1035 | 78 | 2850 | 28 | 6 | 15 | 21 | 6555 | 1 | 21 | 1326 | 10 |
Para entrenar el modelo, se agrega a la tabla de datos el id de cada persona y se quita la información redundante:
Ahora es sencillo filtrar los duplicados reales, esto permite examinar cómo se presentan las inconsistencias reales en los datos y elegir los métodos más apropiados en el entrenamiento del modelo.
| fname_c1 | lname_c1 | by | bm | bd | id |
|---|---|---|---|---|---|
| RENATE | SCHUTE | 1940 | 12 | 29 | 436 |
| RENATE | SCHULTE | 1940 | 12 | 29 | 436 |
| CHRISTINE | PETERS | 1993 | 2 | 5 | 442 |
| CHRISTINE | PETERS | 1993 | 2 | 6 | 442 |
| CHRISTA | SCHWARZ | 1965 | 7 | 13 | 444 |
| CHRISTAH | SCHWARZ | 1965 | 7 | 13 | 444 |
Al calcular la distancia de Levenshtein observamos que la similaridad aún está lejana de 1, mientras que la métrica de Jaro y Winkler produce un mejor resultado de la similaridad.
| Cadena 1 | Cadena 2 | Levenshtein | Jaro-Winkler |
|---|---|---|---|
| SCHUTE | SCHULTE | 0.86 | 0.94 |
| CHRISTA | CHRISTAH | 0.88 | 0.95 |
El algoritmo de Jaro-Winkler tiende a funcionar mejor cuando los errores son de tipeo o diferencias leves. También se puede aplicar codificación fonética como soundex() o cualquiera de las presentadas en este capítulo.
En el siguiente paso se lleva a cabo la comparación de pares utilizando un enfoque de bloqueo supervisado, dado que se dispone de información que indica si cada par de registros corresponde a un duplicado o no. Primero, se organizan los registros en bloques basados en criterios específicos, en este caso la primera letra del nombre y el año de nacimiento, de manera que solo se comparan registros dentro de cada bloque. Luego, se realiza la comparación de los pares dentro de cada bloque, evaluando tanto la igualdad exacta de algunos campos como la similitud textual en aquellos que lo requieren. El resultado es un conjunto de comparaciones que refleja para cada par cuán similares son los registros, considerando la información supervisada disponible para identificar duplicados.
Ahora se calculan pesos probabilísticos para cada par comparado. Este paso estima la probabilidad de que cada par sea un match verdadero, usando un modelo probabilístico basado en la teoría de Fellegi-Sunter.
A partir de las probabilidades se clasifica automáticamente los pares en tres categorías:
- P: Positivo (match verdadero).
- N: Negativo (no match).
- L: Incertidumbre (requiere revisión clerical).
En este caso se especifica un umbral de 0.7, es decir, los pares con probabilidad superior a ese valor se clasifican como positivos.
##
## Deduplication Data Set
##
## 500 records
## 2709 record pairs
##
## 50 matches
## 2659 non-matches
## 0 pairs with unknown status
##
##
## Weight distribution:
##
## [0.2,0.25] (0.25,0.3] (0.3,0.35] (0.35,0.4] (0.4,0.45] (0.45,0.5] (0.5,0.55]
## 2318 0 114 131 30 50 8
## (0.55,0.6] (0.6,0.65] (0.65,0.7] (0.7,0.75] (0.75,0.8] (0.8,0.85] (0.85,0.9]
## 2 10 0 0 35 8 3
##
## 46 links detected
## 0 possible links detected
## 2663 non-links detected
##
## alpha error: 0.080000
## beta error: 0.000000
## accuracy: 0.998523
##
##
## Classification table:
##
## classification
## true status N P L
## FALSE 2659 0 0
## TRUE 4 0 46| Concepto | Valor |
|---|---|
| Número de registros | 500 |
| Número de pares de registros | 2,709 |
| Pares que coinciden (matches) | 50 |
| Pares que no coinciden | 2,659 |
| Pares con estado desconocido | 0 |
Se observa que la gran mayoría de los pares comparados presentan baja evidencia de coincidencia, con 2318 pares concentrados en el intervalo de peso [0.2, 0.25]. Por otra parte, solo 46 pares alcanzan un peso mayor a 0.7, lo que sugiere una alta probabilidad de ser duplicados.
| Estado verdadero | N (No) | P (Posible) | L (Link) |
|---|---|---|---|
| FALSE | 2,659 | 0 | 0 |
| TRUE | 4 | 0 | 46 |
Según la matriz de clasificación, de los 50 pares realmente duplicados, el modelo identificó correctamente a 46, mientras que 4 no fueron detectados, lo que corresponde a una tasa de falsos negativos de \(\alpha = 8\)%. Por otro lado, la tasa de falsos positivos es cero, ya que ningún par no duplicado fue clasificado erróneamente como duplicado.
En conjunto, el modelo alcanzó una exactitud del 99.85%, lo que indica un alto rendimiento en la tarea de deduplicación.
Una vez se ha entrenado el modelo, se puede aplicar una comparación difusa (fuzzy) a todos los datos, para ampliar las posibilidades del ejemplo se usará con la métrica de Jaro-Winkler para todas las variables de cadena (strcmp = TRUE). Se omite el uso de funciones fonéticas (phonetic = FALSE), lo cual es útil cuando queremos detectar errores ortográficos leves y los bloques se arman solo por año de nacimiento. Aunque en la práctica se debe especificar el modelo entrenado.
En conclusión, el uso de bloqueo combinado con comparaciones textuales permite reducir significativamente el esfuerzo computacional, en este caso, más del 90%, al evitar comparaciones innecesarias entre todos los registros. Además, este enfoque es efectivo para detectar duplicados incluso cuando existen errores de tipeo o inconsistencias en los datos, logrando una clasificación precisa de los pares potencialmente duplicados.
Se recomienda ajustar adecuadamente el argumento blockfld para optimizar la eficiencia del proceso, y seleccionar el método de comparación textual (por ejemplo, Jaro-Winkler o Levenshtein) de acuerdo con la calidad y naturaleza de los nombres en los datos.
Finalmente, es importante validar los resultados obtenidos, ya sea mediante revisión clerical o a través de otras reglas, para asegurar la confiabilidad del proceso de deduplicación.
Ejemplo usando el paquete fastLink
Para explorar otras opciones, en este ejemplo se usará el conjunto de datos RLdata10000 del paquete RecordLinkage, el cual contiene 10.000 registros con 1.000 duplicados y 8.000 no duplicados.
| fname_c1 | fname_c2 | lname_c1 | lname_c2 | by | bm | bd |
|---|---|---|---|---|---|---|
| FRANK | NA | MUELLER | NA | 1967 | 9 | 27 |
| MARTIN | NA | SCHWARZ | NA | 1967 | 2 | 17 |
| HERBERT | NA | ZIMMERMANN | NA | 1961 | 11 | 6 |
| HANS | NA | SCHMITT | NA | 1945 | 8 | 14 |
| UWE | NA | KELLER | NA | 2000 | 7 | 5 |
| DANIEL | NA | HEINRICH | NA | 1967 | 5 | 6 |
Al igual que en el ejemplo anterior, suponga que un subconjunto de los datos de la muestra E fue revisado de forma manual para establecer la coincidencia con la muestra P, y que ha conservado un id único que permite realizar el emparejamiento exacto.
En el caso de RLdata10000 se cuenta con el vector identity.RLdata10000 que conserva el id único de cada registro, esto con fines de entrenamiento de un modelo o como en este caso, para mostrar el uso de los procedimientos. Note que solo hay 9.000 identificadores únicos, por lo que 1.000 son duplicados, el desafío es que los métodos de emparejamiento los identifique con el menor error.
## [1] 9000Se define el vector var con todas las variables que se hará el emparejamiento, en el vector char_vars se conservan las variables de cadena donde es posible hacer cálculos con métricas de similaridad, cal_simil especifica para cuales de las variables de char_vars no se exige coincidencias exactas. La métrica que se usa por defecto es Jaro-Winkler, pero hay otras opciones que se pueden implementar.
La función fastLink permite identificar los duplicados usando los mismos datos en los argumentos de los dfA y dfB, y cuenta con un argumento para distribuir en varios cores el procesamiento. cut.a es el umbral mínimo de probabilidad posterior para aceptar un emparejamiento y cut.p es el umbral inferior para considerar un registro como emparejamiento potencial (que pase a revisión clerical), es decir, si la probabilidad está entre cut.p y cut.a, el par se considera un emparejamiento potencial que requiere revisión manual. Si la probabilidad es menor que cut.p, el registro se considera como no emparejado. Se debe tener en cuenta que un valor muy alto de cut.a puede originar más precisión pero menos emparejamientos, pero si cut.a es bajo entonces se espera un mayor recall y un mayor riesgo de falsos positivos.
##
## ====================
## fastLink(): Fast Probabilistic Record Linkage
## ====================
##
## If you set return.all to FALSE, you will not be able to calculate a confusion table as a summary statistic.
## dfA and dfB are identical, assuming deduplication of a single data set.
## Setting return.all to FALSE.
##
## Calculating matches for each variable.
## Getting counts for parameter estimation.
## Parallelizing calculation using OpenMP. 1 threads out of 8 are used.
## Running the EM algorithm.
## Getting the indices of estimated matches.
## Parallelizing calculation using OpenMP. 1 threads out of 8 are used.
## Calculating the posterior for each pair of matched observations.
## Getting the match patterns for each estimated match.El procedimiento genera la variable dedupe.ids para todo el conjunto de datos. La función getMatches permite extraer el conjunto de datos con la variable de identificación.
## dedupe.ids dupe_count fname_c1 fname_c2 lname_c1 lname_c2 by bm bd id
## 1 420 3 GUENTHER <NA> ZIMMERMWANN <NA> 1971 6 23 1794
## 2 420 3 GUENTHER <NA> ZIMMERMANN <NA> 1992 6 23 1864
## 3 420 3 GUENTHER <NA> ZIMMERMANN <NA> 1971 6 23 1794
## 4 3969 3 GERTRUD <NA> MUELLER <NA> 1964 7 27 8970
## 5 3969 3 GERTRUD <NA> MUELOER <NA> 1964 7 11 7616
## 6 3969 3 GERTRUD <NA> MUELLER <NA> 1964 7 11 7616| dedupe.ids | dupe_count | fname_c1 | fname_c2 | lname_c1 | lname_c2 | by | bm | bd | id |
|---|---|---|---|---|---|---|---|---|---|
| 420 | 3 | GUENTHER | ZIMMERMWANN | 1971 | 6 | 23 | 1794 | ||
| 420 | 3 | GUENTHER | ZIMMERMANN | 1992 | 6 | 23 | 1864 | ||
| 420 | 3 | GUENTHER | ZIMMERMANN | 1971 | 6 | 23 | 1794 | ||
| 3969 | 3 | GERTRUD | MUELLER | 1964 | 7 | 27 | 8970 | ||
| 3969 | 3 | GERTRUD | MUELOER | 1964 | 7 | 11 | 7616 | ||
| 3969 | 3 | GERTRUD | MUELLER | 1964 | 7 | 11 | 7616 |
El desempeño del modelo se puede evaluar mediante una matriz de confusión que compara las predicciones del modelo con los valores reales. En este caso, el modelo identificó correctamente 982 verdaderos positivos, es decir, observaciones que efectivamente eran duplicados. Sin embargo, también generó 18 falsos negativos, que son casos verdaderos que el modelo no logró identificar correctamente. Además, el modelo produjo 63 falsos positivos, es decir, casos que fueron clasificados como verdaderos por el modelo, pero en realidad no eran duplicados.
## Modelo
## Real FALSE TRUE
## FALSE 0 63
## TRUE 18 982| Real / Predicho | FALSE | TRUE |
|---|---|---|
| FALSE | 0 | 63 |
| TRUE | 18 | 982 |
5.3.2 Vinculación de registros
Con el fin de integrar la información proveniente de la muestra E y la muestra P, se debe llevar a cabo un proceso de emparejamiento de registros. Este procedimiento es fundamental para identificar unidades observadas en ambas muestras y, de esta manera implementar el modelo basado en el sistema de estimación dual.
El proceso de vinculación de registros entre la muestra E y la muestra P se fundamenta en la comparación de variables clave que están presentes en ambas bases de datos. Entre estas variables se incluyen información como nombres, apellidos, sexo y fecha de nacimiento, las cuales permiten establecer la correspondencia entre los individuos de cada muestra. Estas coincidencias constituyen la base para identificar si un mismo registro aparece en las dos fuentes de información.
La forma de implementar este procedimiento es análoga al utilizado previamente para la detección de duplicados dentro de una misma base de datos. La diferencia principal radica en los conjuntos de datos que se introducen en los argumentos de la función de emparejamiento: en lugar de comparar una base consigo misma, en este caso se contrasta la muestra E frente a la muestra P. De esta manera, se logra identificar registros compartidos entre las dos muestras, manteniendo la misma lógica de comparación, pero adaptada a un contexto de integración de fuentes.
En el caso del paquete RecordLinkage, se cuenta con dos funciones para la creación de patrones de comparación a partir de conjuntos de datos: compare.dedup() o RLBigDataDedup(), para la deduplicación de un único conjunto de datos como se presentó en la sección anterior, y compare.linkage() o RLBigDataLinkage(), para vincular dos conjuntos de datos diferentes, la diferencia es que la segunda función está diseñada para grandes conjuntos de datos.
Considere los conjuntos de datos de la muestra E y de la muestra P, almacenados previamente en los objetos censo_limpio y encuesta_limpia. Ahora se creará la variable de fecha con el valor de la fecha de nacimiento.
Para el ejemplo se usará el paquete RecordLinkage. En este caso la muestra P contiene 54 registros y la muestra E contiene 97 registros, en este caso se aplicará una indexación usando como bloques el id_segmento. La estructura de la base de la muestra E es la siguiente
| id_segmento | nombre_cod | apellido_cod | sexo | fecha_nacimiento |
|---|---|---|---|---|
| 101 | KRLS | PRS | m | 1947-01-01 |
| 101 | LK | KSTR | f | 1975-01-01 |
| 101 | KML | KSTR | f | 2012-01-01 |
| 101 | MR | KSTR | f | 1959-01-01 |
| 102 | YRG | GMS | m | 1954-01-01 |
| 102 | SF | RMRS | f | 2000-01-01 |
Mientras que la muestra P es la siguiente, es de recordar que los conjuntos de datos ya fueron sometidos a un preprocesamiento, y note que los conjuntos de datos se han alineado para que las variables se denominen de la misma forma:
| id_segmento | nombre_cod | apellido_cod | sexo | fecha_nacimiento |
|---|---|---|---|---|
| 101 | MR | KSTR | f | 1959-01-01 |
| 101 | KRLS | PRS | m | 1947-01-01 |
| 101 | LK | KSTR | f | 1975-01-01 |
| 101 | KML | RMRS | f | 2010-01-01 |
| 101 | SF | KSTR | f | 1966-01-01 |
| 101 | N | MRTNS | f | 1973-01-01 |
La función compare.linkage() construye los patrones para la vinculación de los registros, en este caso se compara la muestra E y la muestra P usando como bloque el segmento.
Una vez realizadas las comparaciones utilizando los criterios especificados, se aplica el algoritmo para calcular la probabilidad de coincidencia. Para ello, el paquete RecordLinkage cuenta con los algoritmos de Fellegi-Sunter, EpiLink y EM.
##
## Linkage Data Set
##
## 54 records in data set 1
## 97 records in data set 2
## 1750 record pairs
##
## 0 matches
## 0 non-matches
## 1750 pairs with unknown status
##
##
## Weight distribution:
##
## [-16,-14] (-14,-12] (-12,-10] (-10,-8] (-8,-6] (-6,-4] (-4,-2] (-2,0]
## 743 0 601 114 0 217 0 1
## (0,2] (2,4] (4,6] (6,8] (8,10] (10,12] (12,14]
## 0 18 2 0 1 0 53| Intervalo de peso | Número de pares |
|---|---|
| -16 – -14 | 743 |
| -14 – -12 | 0 |
| -12 – -10 | 601 |
| -10 – -8 | 114 |
| -8 – -6 | 0 |
| -6 – -4 | 217 |
| -4 – -2 | 0 |
| -2 – 0 | 1 |
| 0 – 2 | 0 |
| 2 – 4 | 18 |
| 4 – 6 | 2 |
| 6 – 8 | 0 |
| 8 – 10 | 1 |
| 10 – 12 | 0 |
| 12 – 14 | 53 |
El análisis de la distribución de los pesos muestra que, aunque la mayoría de los pares se concentran en valores negativos, lo que indica una baja similitud y, por tanto, una baja probabilidad de coincidencia. Hay algunos pares que alcanzan valores positivos, y dentro de estos, se observa que algunos se ubican en el rango más alto, por lo que tienen una alta probabilidad de ser emparejamientos verdaderos.
Cuando los conjuntos de datos son muy grandes, se puede usar un enfoque basado en la función RLBigDataLinkage en vez de compare.linkage, solo debe tener en cuenta que al ser objetos S4 debe ver los resultados usando el simbolo @, por ejemplo summary(empareja_fs@Wdata).
Los algoritmos calculan la probabilidad de coincidencia para cada registro en df_encuesta con cada registro en el conjunto de df_censo cuando pertenecen al mismo segmento, basándose en los patrones de comparación especificados. Ahora, es necesario realizar la clasificación como emparejado, emparejamiento potencial o no emparejado. Para hacer esta clasificación, es necesario establecer el umbral de clasificación.
La elección del umbral suele ser un aspecto relevante. Si es muy bajo, se podría estar aceptando demasiados falsos positivos; si es muy alto, se podría perder verdaderos emparejados. una de las herramientas del paquete RecordLinkage es la función getParetoThreshold(), que puede ser útil para identificar el umbral de aceptación. Sin embargo, con conjuntos de datos grandes podría tardar mucho en ejecutarse.
La siguiente gráfica es interactiva y permite observar cómo cambia la vida residual media a medida que sube el umbral. Se ha comentado la línea debido a que no puede compilarse por bookdown, y se ha tomado el umbral automático. La idea básica es identificar el punto de cambio de la pendiente en la curva, para ello puede usar un criterio como el del codo.
Una vez definido el umbral, se puede extraer en un conjunto de datos a los registros clasificados como emparejados. La primera fila corresponde al registro en df_encuesta mientras que el segundo corresponde al registro en df_censo.
| Registros emparejados | ||||||
| id | id_segmento | nombre_cod | apellido_cod | sexo | fecha_nacimiento | Weight |
|---|---|---|---|---|---|---|
| 1 | 101 | MR | KSTR | f | 1959-01-01 | |
| 4 | 101 | MR | KSTR | f | 1959-01-01 | 13.278591201562502 |
| 2 | 101 | KRLS | PRS | m | 1947-01-01 | |
| 1 | 101 | KRLS | PRS | m | 1947-01-01 | 13.278591201562502 |
| 3 | 101 | LK | KSTR | f | 1975-01-01 | |
| 2 | 101 | LK | KSTR | f | 1975-01-01 | 13.278591201562502 |
| 4 | 101 | KML | RMRS | f | 2010-01-01 | |
| 87 | 101 | KML | RMRS | f | 2010-01-01 | 13.278591201562502 |
| 5 | 101 | SF | KSTR | f | 1966-01-01 | |
| 9 | 101 | SF | KSTR | f | 1966-01-01 | 13.278591201562502 |
| 6 | 101 | N | MRTNS | f | 1973-01-01 | |
| 12 | 101 | N | MRTNS | f | 1973-01-01 | 13.278591201562502 |
| 7 | 101 | LK | MRN | f | 2003-01-01 | |
| 21 | 101 | LK | MRN | f | 2003-01-01 | 13.278591201562502 |
| 8 | 101 | YRG | MRN | m | 1955-01-01 | |
| 19 | 101 | YRG | MRN | m | 1955-01-01 | 13.278591201562502 |
| 9 | 101 | NDRS | KSTR | m | 1936-01-01 | |
| 28 | 101 | NDRS | KSTR | m | 1936-01-01 | 13.278591201562502 |
| 10 | 101 | N | TRS | f | 2017-01-01 | |
| 29 | 101 | N | TRS | f | 2017-01-01 | 13.278591201562502 |
| 11 | 101 | N | MRTNS | f | 2001-01-01 | |
| 42 | 101 | N | MRTNS | f | 2001-01-01 | 13.278591201562502 |
| 12 | 101 | YN | KSTR | m | 2015-01-01 | |
| 41 | 101 | YN | KSTR | m | 2015-01-01 | 13.278591201562502 |
| 13 | 101 | PDR | LPS | m | 2001-01-01 | |
| 50 | 101 | PDR | LPS | m | 2001-01-01 | 13.278591201562502 |
| 14 | 101 | PDR | RMRS | m | 2018-01-01 | |
| 51 | 101 | PDR | RMRS | m | 2018-01-01 | 13.278591201562502 |
| 15 | 101 | YRG | KSTR | m | 1946-01-01 | |
| 59 | 101 | YRG | KSTR | m | 1946-01-01 | 13.278591201562502 |
| 16 | 101 | YRG | KSTR | m | 1988-01-01 | |
| 57 | 101 | YRG | KSTR | m | 1988-01-01 | 13.278591201562502 |
| 17 | 101 | SF | GMS | f | 2007-01-01 | |
| 70 | 101 | SF | GMS | f | 2007-01-01 | 13.278591201562502 |
| 18 | 101 | YRG | TRS | m | 1969-01-01 | |
| 79 | 101 | YRG | TRS | m | 1969-01-01 | 13.278591201562502 |
| 19 | 102 | YRG | GMS | m | 1954-01-01 | |
| 5 | 102 | YRG | GMS | m | 1954-01-01 | 13.278591201562502 |
| 20 | 102 | N | RMRS | f | 1963-01-01 | |
| 92 | 102 | N | RMRS | f | 1963-01-01 | 13.278591201562502 |
| 21 | 102 | N | GRK | f | 1985-01-01 | |
| 13 | 102 | N | GRK | f | 1985-01-01 | 13.278591201562502 |
| 22 | 102 | KRLS | RMRS | m | 1942-01-01 | |
| 23 | 102 | KRLS | RMRS | m | 1942-01-01 | 13.278591201562502 |
| 23 | 102 | YN | KSTR | m | 2006-01-01 | |
| 32 | 102 | YN | KSTR | m | 2006-01-01 | 13.278591201562502 |
| 24 | 102 | PDR | MRN | m | 1990-01-01 | |
| 34 | 102 | PDR | MRN | m | 1990-01-01 | 13.278591201562502 |
| 25 | 102 | MR | LPS | f | 1935-01-01 | |
| 45 | 102 | MR | LPS | f | 1935-01-01 | 13.278591201562502 |
| 26 | 102 | NDRS | GRK | m | 2020-01-01 | |
| 44 | 102 | NDRS | GRK | m | 2020-01-01 | 13.278591201562502 |
| 27 | 102 | PDR | RDRGS | m | 2025-01-01 | |
| 46 | 102 | PDR | RDRGS | m | 2025-01-01 | 13.278591201562502 |
| 28 | 102 | YN | GRK | m | 2009-01-01 | |
| 53 | 102 | YN | GRK | m | 2009-01-01 | 13.278591201562502 |
| 29 | 102 | YRG | LPS | m | 1987-01-01 | |
| 64 | 102 | YRG | LPS | m | 1987-01-01 | 13.278591201562502 |
| 30 | 102 | KRLS | RDRGS | m | 1985-01-01 | |
| 62 | 102 | KRLS | RDRGS | m | 1985-01-01 | 13.278591201562502 |
| 31 | 102 | PDR | GMS | m | 1983-01-01 | |
| 63 | 102 | PDR | GMS | m | 1983-01-01 | 13.278591201562502 |
| 32 | 102 | KML | TRS | f | 1973-01-01 | |
| 71 | 102 | KML | TRS | f | 1973-01-01 | 13.278591201562502 |
| 33 | 102 | YRG | TRS | m | 1976-01-01 | |
| 74 | 102 | YRG | TRS | m | 1976-01-01 | 13.278591201562502 |
| 34 | 102 | N | MRN | f | 1998-01-01 | |
| 72 | 102 | N | MRN | f | 1998-01-01 | 13.278591201562502 |
| 35 | 102 | N | GRK | f | 1990-01-01 | |
| 83 | 102 | N | GRK | f | 1990-01-01 | 13.278591201562502 |
| 36 | 102 | LK | PRS | f | 2020-01-01 | |
| 82 | 102 | LK | PRS | f | 2020-01-01 | 13.278591201562502 |
| 38 | 103 | KRLS | MRN | m | 1950-01-01 | |
| 7 | 103 | KRLS | MRN | m | 1950-01-01 | 13.278591201562502 |
| 39 | 103 | YN | PRS | m | 1945-01-01 | |
| 96 | 103 | YN | PRS | m | 1945-01-01 | 13.278591201562502 |
| 40 | 103 | KML | KSTR | f | 1974-01-01 | |
| 17 | 103 | KML | KSTR | f | 1974-01-01 | 13.278591201562502 |
| 41 | 103 | MR | PRS | f | 1994-01-01 | |
| 25 | 103 | MR | PRS | f | 1994-01-01 | 13.278591201562502 |
| 42 | 103 | PDR | MRN | m | 1939-01-01 | |
| 38 | 103 | PDR | MRN | m | 1939-01-01 | 13.278591201562502 |
| 43 | 103 | NDRS | PRS | m | 2010-01-01 | |
| 37 | 103 | NDRS | PRS | m | 2010-01-01 | 13.278591201562502 |
| 44 | 103 | PDR | GMS | m | 2009-01-01 | |
| 48 | 103 | PDR | GMS | m | 2009-01-01 | 13.278591201562502 |
| 45 | 103 | SF | MRTNS | f | 1962-01-01 | |
| 49 | 103 | SF | MRTNS | f | 1962-01-01 | 13.278591201562502 |
| 46 | 103 | KRLS | MRN | m | 1995-01-01 | |
| 47 | 103 | KRLS | MRN | m | 1995-01-01 | 13.278591201562502 |
| 47 | 103 | PDR | KSTR | m | 2009-01-01 | |
| 54 | 103 | PDR | KSTR | m | 2009-01-01 | 13.278591201562502 |
| 48 | 103 | PDR | MRN | m | 2024-01-01 | |
| 55 | 103 | PDR | MRN | m | 2024-01-01 | 13.278591201562502 |
| 49 | 103 | YN | LPS | m | 1977-01-01 | |
| 56 | 103 | YN | LPS | m | 1977-01-01 | 13.278591201562502 |
| 50 | 103 | N | PRS | f | 2000-01-01 | |
| 67 | 103 | N | PRS | f | 2000-01-01 | 13.278591201562502 |
| 51 | 103 | LK | MRN | f | 1967-01-01 | |
| 78 | 103 | LK | MRN | f | 1967-01-01 | 13.278591201562502 |
| 52 | 103 | MR | LPS | f | 1945-01-01 | |
| 76 | 103 | MR | LPS | f | 1945-01-01 | 13.278591201562502 |
| 53 | 103 | N | MRTNS | f | 2001-01-01 | |
| 84 | 103 | N | MRTNS | f | 2001-01-01 | 13.278591201562502 |
| 54 | 103 | NDRS | LPS | m | 2022-01-01 | |
| 85 | 103 | NDRS | LPS | m | 2022-01-01 | 13.278591201562502 |
| 37 | 102 | NDRS | LPS | f | 1986-01-01 | |
| 81 | 102 | NDRS | LPS | m | 1986-01-01 | 9.030663688118919 |
| 44 | 103 | PDR | GMS | m | 2009-01-01 | |
| 54 | 103 | PDR | KSTR | m | 2009-01-01 | 5.860738686676607 |
| 47 | 103 | PDR | KSTR | m | 2009-01-01 | |
| 48 | 103 | PDR | GMS | m | 2009-01-01 | 5.860738686676607 |
De igual forma, usando la misma gráfica obtenida con getParetoThreshold() se puede establecer un umbral más flexible, y encontrar los emparejamientos potenciales. En nuestro ejemplo se tomarán como aquellos registros que tienen un ponderador entre 1.2 y el umbral, los cuales pasarán a una revisión clerical para establecer si se clasifican como emparejados o no emparejados
| Emparejamientos potenciales | ||||||
| id | id_segmento | nombre_cod | apellido_cod | sexo | fecha_nacimiento | Weight |
|---|---|---|---|---|---|---|
| 6 | 101 | N | MRTNS | f | 1973-01-01 | |
| 42 | 101 | N | MRTNS | f | 2001-01-01 | 3.123773092510401 |
| 9 | 101 | NDRS | KSTR | m | 1936-01-01 | |
| 40 | 101 | NDRS | KSTR | m | 1949-01-01 | 3.123773092510401 |
| 11 | 101 | N | MRTNS | f | 2001-01-01 | |
| 12 | 101 | N | MRTNS | f | 1973-01-01 | 3.123773092510401 |
| 12 | 101 | YN | KSTR | m | 2015-01-01 | |
| 10 | 101 | YN | KSTR | m | 1973-01-01 | 3.123773092510401 |
| 13 | 101 | PDR | LPS | m | 2001-01-01 | |
| 11 | 101 | PDR | LPS | m | 2019-01-01 | 3.123773092510401 |
| 14 | 101 | PDR | RMRS | m | 2018-01-01 | |
| 58 | 101 | PDR | RMRS | m | 1962-01-01 | 3.123773092510401 |
| 15 | 101 | YRG | KSTR | m | 1946-01-01 | |
| 57 | 101 | YRG | KSTR | m | 1988-01-01 | 3.123773092510401 |
| 16 | 101 | YRG | KSTR | m | 1988-01-01 | |
| 59 | 101 | YRG | KSTR | m | 1946-01-01 | 3.123773092510401 |
| 21 | 102 | N | GRK | f | 1985-01-01 | |
| 83 | 102 | N | GRK | f | 1990-01-01 | 3.123773092510401 |
| 23 | 102 | YN | KSTR | m | 2006-01-01 | |
| 43 | 102 | YN | KSTR | m | 2012-01-01 | 3.123773092510401 |
| 35 | 102 | N | GRK | f | 1990-01-01 | |
| 13 | 102 | N | GRK | f | 1985-01-01 | 3.123773092510401 |
| 36 | 102 | LK | PRS | f | 2020-01-01 | |
| 16 | 102 | LK | PRS | f | 1966-01-01 | 3.123773092510401 |
| 38 | 103 | KRLS | MRN | m | 1950-01-01 | |
| 47 | 103 | KRLS | MRN | m | 1995-01-01 | 3.123773092510401 |
| 40 | 103 | KML | KSTR | f | 1974-01-01 | |
| 26 | 103 | KML | KSTR | f | 2019-01-01 | 3.123773092510401 |
| 42 | 103 | PDR | MRN | m | 1939-01-01 | |
| 55 | 103 | PDR | MRN | m | 2024-01-01 | 3.123773092510401 |
| 43 | 103 | NDRS | PRS | m | 2010-01-01 | |
| 18 | 103 | NDRS | PRS | m | 2004-01-01 | 3.123773092510401 |
| 46 | 103 | KRLS | MRN | m | 1995-01-01 | |
| 7 | 103 | KRLS | MRN | m | 1950-01-01 | 3.123773092510401 |
| 48 | 103 | PDR | MRN | m | 2024-01-01 | |
| 38 | 103 | PDR | MRN | m | 1939-01-01 | 3.123773092510401 |
Finalizado el proceso, los registros que se lograron emparejar deben ser retirados del conjunto de datos df_encuesta y el conjunto df_censo debe ampliarse con otros segmentos aledaños a la muestra E, para repetir el proceso.
Referencias
Una entidad puede ser un hogar, una persona, una empresa u otro tipo de unidad registrada.↩︎