6.2 Flujo general
La Figura 6.1 muestra los pasos principales del proceso de emparejamiento. El primer paso es el preprocesamiento de datos, cuyo objetivo es asegurar que los datos de ambas fuentes estén en un formato uniforme y comparable.
El segundo paso se conoce como indexación, acá se busca reducir la complejidad cuadrática del proceso de emparejamiento mediante el uso de estructuras de datos que permiten generar de manera eficiente y efectiva pares de registros candidatos que probablemente correspondan a la misma persona.
En el tercer paso, se realiza la comparación de pares de registros, donde los pares candidatos generados a partir de la indexación se comparan utilizando varias variables.
En el paso de clasificación, los pares de registros se asignan a una de tres categorías: emparejados, no emparejados y emparejamientos potenciales. Si los pares se clasifican como emparejamientos potenciales, se requiere una revisión clerical manual para decidir su estado final (emparejado o no emparejado). En el paso final, se analiza la calidad y la completitud de los datos emparejados.
Para la deduplicación de una única base de datos, todos los pasos del proceso de vinculación siguen siendo aplicables. El preprocesamiento es esencial para asegurar que la base completa esté estandarizada, especialmente si los registros han sido ingresados en diferentes momentos, lo que puede haber introducido variaciones en los formatos o en los métodos de captura de datos. La etapa de indexación también es crítica en la deduplicación, ya que comparar cada registro con todos los demás implica un alto costo computacional.
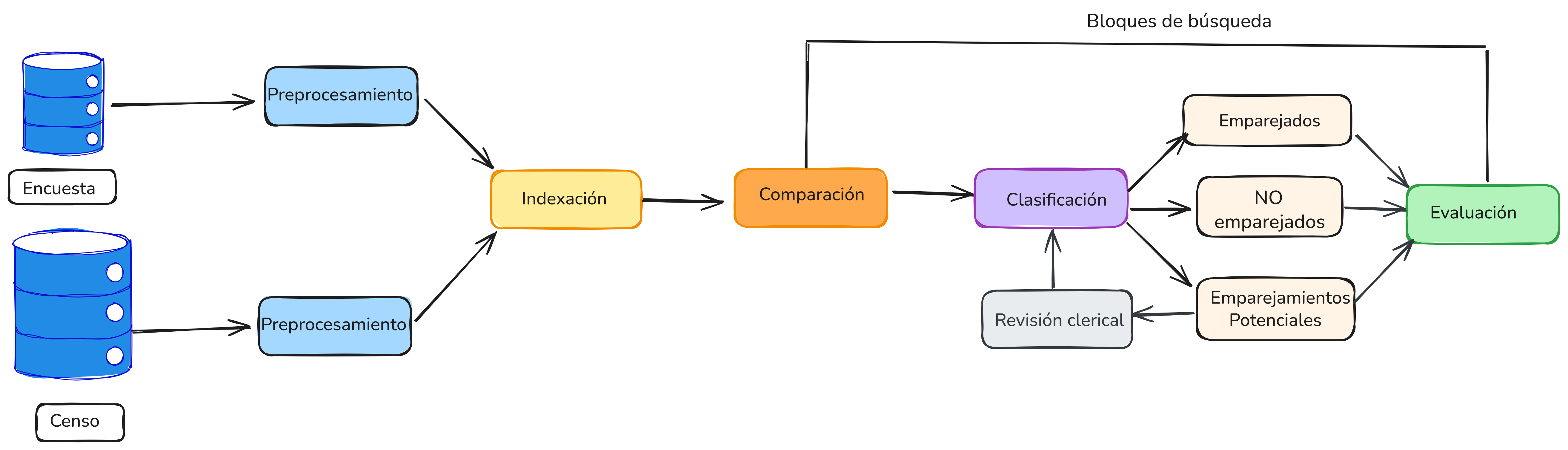
Figure 6.1: Flujo general del proceso de emparejamiento
Para ilustrar las tareas involucradas a lo largo del proceso de emparejamiento de registros, se utilizará un ejemplo compuesto por dos tablas de datos artificiales.
A continuación se presenta la estructura para los primeros registros de la tabla censo:
| Tabla censo | |||||||||
| id_segmento | id_hogar | id_censo | nombre | apellido | sexo | anio_nac | mes_nac | dia_nac | parentesco |
|---|---|---|---|---|---|---|---|---|---|
| 101 | H101_1 | c1 | Carlos | Pérez | M | 1947 | 1 | 1 | Jefe |
| 101 | H101_1 | c2 | Lucía | Castro | F | 1975 | 1 | 1 | Hijo/a |
| 101 | H101_1 | c3 | Camila | Castro | F | 2012 | 1 | 1 | Hijo/a |
| 101 | H101_1 | c4 | María | Castro | F | 1959 | 1 | 1 | Nieto/a |
| 102 | H102_1 | c5 | Jorge | Gómez | M | 1954 | 1 | 1 | Jefe |
| 102 | H102_1 | c6 | Sofía | Ramírez | F | 2000 | 1 | 1 | Hijo/a |
La tabla encuesta presenta la siguiente estructura para los primeros registros:
| Tabla encuesta | ||||||
| id_segmento | id_hogar | id_encuesta | nombre_completo | sexo | fecha_nacimiento | parentesco |
|---|---|---|---|---|---|---|
| 101 | H101_1 | e1 | María Castro | F | 1959-1-1 | Nieto/a |
| 101 | H101_1 | e2 | Carlos Pérez | M | 1947-1-1 | Jefe |
| 101 | H101_1 | e3 | Lucía Castro | F | 1975-1-1 | Hijo/a |
| 101 | H101_10 | e4 | Camila Ramírez | F | 2010-1-1 | Hijo/a |
| 101 | H101_2 | e5 | Sofíá Cástro | F | 1966-1-1 | Jefe |
| 101 | H101_2 | e6 | Ana Martínez | F | 1973-1-1 | Cónyuge |
El objetivo es realizar un proceso de emparejamiento de las dos tablas anteriores. Como puede observarse, aunque ambas contienen información sobre nombre, apellido, sexo, fecha de nacimiento, parentesco y barrio, la estructura de las dos tablas es diferente, al igual que el formato de los valores almacenados en algunas de ellas.