5.3 Protocolo de clasificación
El protocolo operativo para clasificar registros como correctos o incorrectos implica tres grandes fases: preprocesamiento de datos, emparejamiento de registros, y evaluación de coincidencias.
5.3.1 Preprocesamiento de datos
Esta fase estandariza y valida la información recolectada, y prepara las bases para el emparejamiento:
- Geocodificación: Consiste en validar que las direcciones estén en los segmentos de la muestra.
- Consistencia Lógica: Busca asegurar que los datos tengan una consistencia desde la lógica de la composición del hogar, edades y relaciones. por ejemplo, verificar que las relaciones de parentesco sean coherentes un hijo/a no puede ser mayor que el jefe de hogar, validar que las edades sean consistentes con las fechas de nacimiento, revisar inconsistencias en la estructura del hogar como que un hogar no puede tener más de un jefe de hogar.
- Normalización de nombres: Se establecen reglas para que los nombres y los apellidos sea válidos. Por ejemplo, que mínimo el primer nombre y primer apellido tengan al menos dos caracteres, eliminar caracteres especiales, espacios innecesarios y normalizar formatos como convertir todo a mayúsculas o minúsculas.
- Estandarización: Consiste en verificar y ajustar los formatos de fechas, sexo, edad y las demás variables que se usarán en el emparejamiento. Por ejemplo, los formatos de fechas deben estar en formato DD/MM/AAAA, unificar categorías de variables categóricas que puedan originar errores (sexo: “M” para masculino, “F” para femenino), revisar y ajustar errores tipográficos o de codificación en variables clave como edad, sexo y relación de parentesco.
- Identificación de duplicados: Detectar registros múltiples del mismo individuo.
- Casos no válidos: Busca identificar individuos ficticios o registros que no corresponden a personas (mascotas, errores de registro, etc).
- Análisis descriptivo: Presentar los resultados del preprocesamiento con el fin de establecer las frecuencias de los valores faltantes. Por ejemplo, porcentaje de registros sin fecha de nacimiento, sin primer nombre, sin segundo nombre, sin departamento, etc.
- Tratamiento de datos faltantes: Imputar datos faltantes o excluir registros no recuperables. Estos corresponden a registros donde no se puede determinar si la enumeración es correcta o incorrecta debido a falta de información. Es importante que exista la evidencia de la decisión, esto se obtiene al marcar los registros con un estado de “imputado” o “excluido”.
5.3.2 Emparejamiento de registros
Esta etapa inicia con la muestra E y muestra P. Si al final del proceso existen registros que no se han logrado emparejar, entonces la muestra E se amplia a otras áreas para identificar si la persona encontrada en la muestra P si fue censada pero en un segmento diferente. A continuación se enuncian las etapas del proceso.
- Determinístico (exacto): Establecer las variables que se usarán para establecer las coincidencias exactas. Es recomendable que el censo y la encuesta de cobertura levanten información sobre el tipo de documento y número de documento de identidad, esto ayuda a que el proceso de emparejamiento sea más efectivo.
- Probabilístico: Usar técnicas de vinculación para los registros (record linkage), para los registros que no tuvieron una coincidencia exacta.
- Áreas o bloques de búsqueda: Establecer reglas para limitar el emparejamiento a segmentos censales y áreas adyacentes.
- Definición del umbral: Definir el umbral para establecer las coincidencias es un aspecto relevante, el propósito es minimizar la probabilidad de que un emparejamiento erróneo. En este caso se pueden establecer algunas reglas, si la probabilidad de emparejamiento es superior al 99% se considera “emparejado”, si está entre el 90% y 99% se considera “emparejamiento potencial” y si está por debajo del 90% se considera “no emparejado”.
- Revisión clerical y clasificación: Los registros marcados como “emparejamiento potencial” son revisadas por personal capacitado.
La Figura 5.1 presenta una ilustración general de las fases del proceso de emparejamiento y revisión clerical.
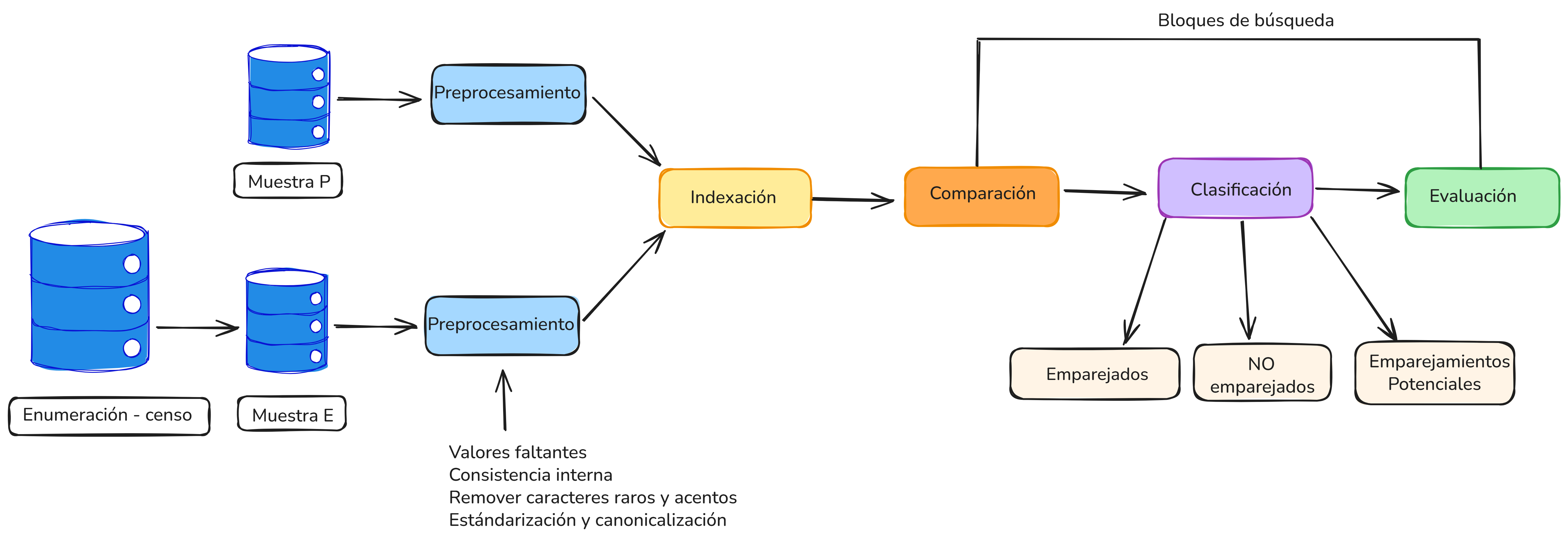
Figure 5.1: Flujo general del proceso de emparejamiento en la encuesta de cobertura
Para los registros que tienen estado “no emparejado” se amplia el área de búsqueda hasta llegar al nivel nacional. Como las probabilidades de error de emparejamiento se incrementan cuando se aumenta el área de búsqueda, es recomendable que se haga una revisión clerical de estos registros luego de ser emparejados, incluso si su probabilidad es alta.
Si no hay coincidencia tras ampliar el área de búsqueda, el caso se clasifica como omisión, es decir, personas que no estuvieron enumeradas en el censo.