Metodología de Benchmarking
- Conteos de personas agregados por dam2, personas mayores de 15 años de edad.
conteo_pp_dam <- readRDS("Recursos/Día5/Sesion1/Data/censo_mrp_dam2.rds") %>%
filter(edad > 1) %>%
group_by(dam , dam2) %>%
summarise(pp_dam2 = sum(n),.groups = "drop")
conteo_pp_dam <- inner_join(conteo_pp_dam,region) %>%
group_by(region) %>%
mutate(pp_region = sum(pp_dam2))
head(conteo_pp_dam) %>% tba()
|
dam
|
dam2
|
pp_dam2
|
region
|
pp_region
|
|
01
|
00101
|
717099
|
10
|
2366172
|
|
02
|
00201
|
61287
|
05
|
697131
|
|
02
|
00202
|
7470
|
05
|
697131
|
|
02
|
00203
|
11799
|
05
|
697131
|
|
02
|
00204
|
13547
|
05
|
697131
|
|
02
|
00205
|
10697
|
05
|
697131
|
- Estimación del parámetro
theta al nivel que la encuesta sea representativa.
indicador_agregado <-
diseno %>% group_by(region) %>%
filter(empleo %in% c(1:3)) %>%
summarise(
Ocupado = survey_ratio(numerator = (empleo == 1),
denominator = 1 ),
Desocupado = survey_ratio(numerator =( empleo == 2),denominator = 1
),
Inactivo = survey_ratio(numerator = (empleo == 3), denominator = 1
)
) %>% select(region,Ocupado,Desocupado, Inactivo)
tba(indicador_agregado)
|
region
|
Ocupado
|
Desocupado
|
Inactivo
|
|
01
|
0.5537
|
0.0236
|
0.4227
|
|
02
|
0.5492
|
0.0349
|
0.4159
|
|
03
|
0.5236
|
0.0855
|
0.3909
|
|
04
|
0.5136
|
0.0337
|
0.4526
|
|
05
|
0.4623
|
0.0423
|
0.4954
|
|
06
|
0.4999
|
0.0298
|
0.4703
|
|
07
|
0.5295
|
0.0174
|
0.4532
|
|
08
|
0.5639
|
0.0678
|
0.3683
|
|
09
|
0.5257
|
0.0505
|
0.4238
|
|
10
|
0.5144
|
0.0402
|
0.4453
|
Organizando la salida como un vector.
temp <-
gather(indicador_agregado, key = "agregado", value = "estimacion", -region) %>%
mutate(nombre = paste0("region_", region,"_", agregado))
Razon_empleo <- setNames(temp$estimacion, temp$nombre)
- Definir los pesos por dominios.
names_cov <- "region"
estimaciones_mod <- estimaciones %>% transmute(
region,
dam2,Ocupado_mod,Desocupado_mod,Inactivo_mod) %>%
inner_join(conteo_pp_dam ) %>%
mutate(wi = pp_dam2/pp_region)
- Crear variables dummys
estimaciones_mod %<>%
fastDummies::dummy_cols(select_columns = names_cov,
remove_selected_columns = FALSE)
Xdummy <- estimaciones_mod %>% select(matches("region_")) %>%
mutate_at(vars(matches("_\\d")) ,
list(Ocupado = function(x) x*estimaciones_mod$Ocupado_mod,
Desocupado = function(x) x*estimaciones_mod$Desocupado_mod,
Inactivo = function(x) x*estimaciones_mod$Inactivo_mod)) %>%
select((matches("Ocupado|Desocupado|Inactivo")))
head(Xdummy) %>% tba()
|
region_01_Ocupado
|
region_02_Ocupado
|
region_03_Ocupado
|
region_04_Ocupado
|
region_05_Ocupado
|
region_06_Ocupado
|
region_07_Ocupado
|
region_08_Ocupado
|
region_09_Ocupado
|
region_10_Ocupado
|
region_01_Desocupado
|
region_02_Desocupado
|
region_03_Desocupado
|
region_04_Desocupado
|
region_05_Desocupado
|
region_06_Desocupado
|
region_07_Desocupado
|
region_08_Desocupado
|
region_09_Desocupado
|
region_10_Desocupado
|
region_01_Inactivo
|
region_02_Inactivo
|
region_03_Inactivo
|
region_04_Inactivo
|
region_05_Inactivo
|
region_06_Inactivo
|
region_07_Inactivo
|
region_08_Inactivo
|
region_09_Inactivo
|
region_10_Inactivo
|
|
0.5217
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0496
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.4287
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
0.5035
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0477
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.4488
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
0.5703
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0240
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.4057
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
0.5300
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0271
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.4428
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
0.5267
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0241
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.4493
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
0.5973
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.0605
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.3422
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
- Calcular el ponderador para cada nivel de la variable.
Ocupado
library(sampling)
names_ocupado <- grep(pattern = "_O", x = colnames(Xdummy),value = TRUE)
gk_ocupado <- calib(Xs = Xdummy[,names_ocupado] %>% as.matrix(),
d = estimaciones_mod$wi,
total = Razon_empleo[names_ocupado] %>% as.matrix(),
method="linear",max_iter = 5000)
checkcalibration(Xs = Xdummy[,names_ocupado] %>% as.matrix(),
d =estimaciones_mod$wi,
total = Razon_empleo[names_ocupado] %>% as.matrix(),
g = gk_ocupado,)
Desocupado
names_descupados <- grep(pattern = "_D", x = colnames(Xdummy),value = TRUE)
gk_desocupado <- calib(Xs = Xdummy[,names_descupados]%>% as.matrix(),
d = estimaciones_mod$wi,
total = Razon_empleo[names_descupados]%>% as.matrix(),
method="linear",max_iter = 5000)
checkcalibration(Xs = Xdummy[,names_descupados]%>% as.matrix(),
d =estimaciones_mod$wi,
total = Razon_empleo[names_descupados]%>% as.matrix(),
g = gk_desocupado,)
Inactivo
names_inactivo <- grep(pattern = "_I", x = colnames(Xdummy),value = TRUE)
gk_Inactivo <- calib(Xs = Xdummy[,names_inactivo]%>% as.matrix(),
d = estimaciones_mod$wi,
total = Razon_empleo[names_inactivo]%>% as.matrix(),
method="linear",max_iter = 5000)
checkcalibration(Xs = Xdummy[,names_inactivo]%>% as.matrix(),
d =estimaciones_mod$wi,
total = Razon_empleo[names_inactivo]%>% as.matrix(),
g = gk_Inactivo,)
- Validar los resultados obtenidos.
par(mfrow = c(1,3))
hist(gk_ocupado)
hist(gk_desocupado)
hist(gk_Inactivo)
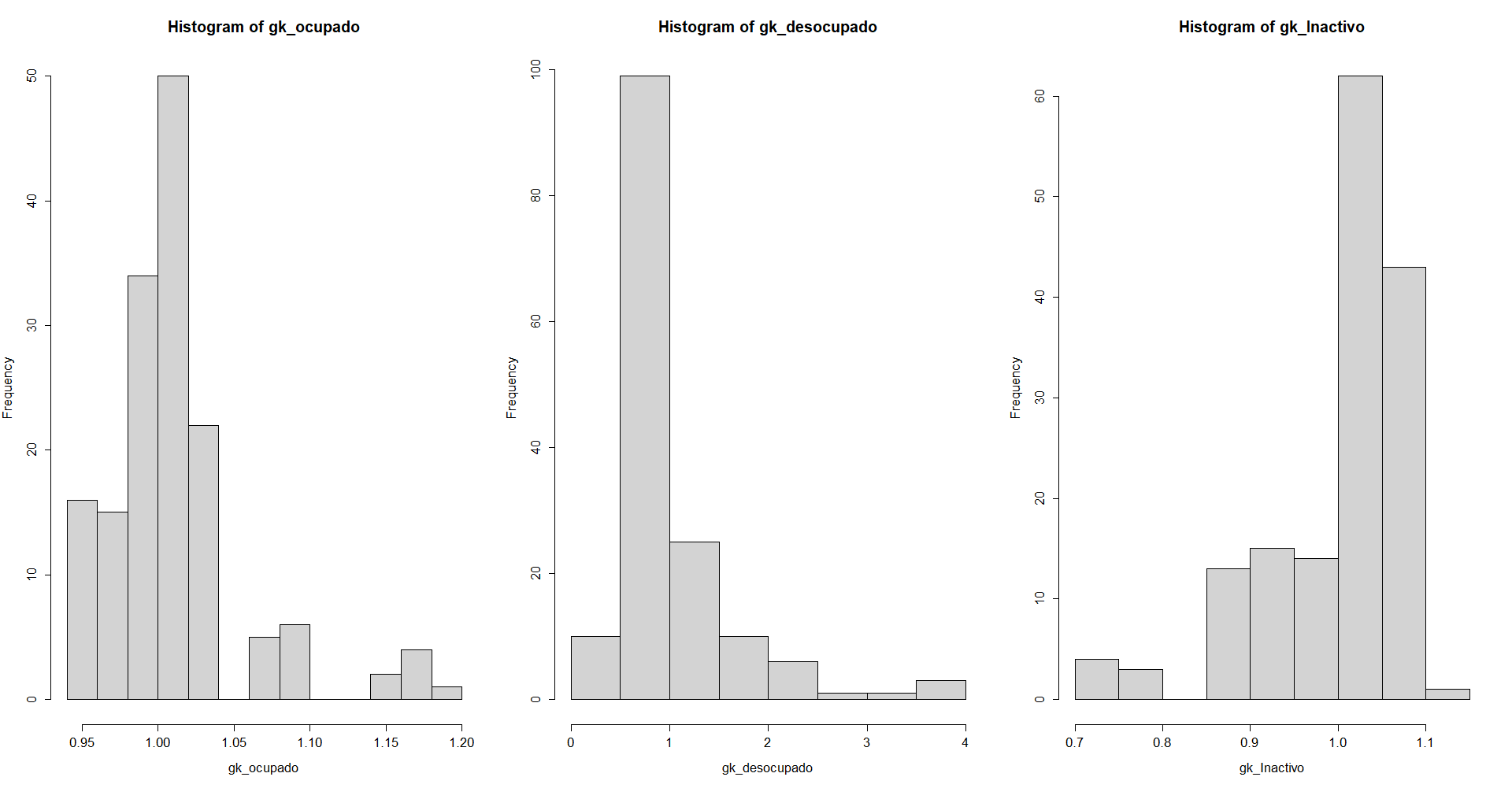
- Estimaciones ajustadas por el ponderador
estimacionesBench <- estimaciones_mod %>%
mutate(gk_ocupado, gk_desocupado, gk_Inactivo) %>%
transmute(
region,
dam,
dam2,
wi,gk_ocupado, gk_desocupado, gk_Inactivo,
Ocupado_Bench = Ocupado_mod*gk_ocupado,
Desocupado_Bench = Desocupado_mod*gk_desocupado,
Inactivo_Bench = Inactivo_mod*gk_Inactivo
)
- Validación de resultados.
estimacionesBench %>%
group_by(region) %>%
summarise(Ocupado_Bench = sum(wi*Ocupado_Bench),
Desocupado_Bench = sum(wi*Desocupado_Bench),
Inactivo_Bench = sum(wi*Inactivo_Bench)) %>%
inner_join(indicador_agregado) %>% tba()
|
region
|
Ocupado_Bench
|
Desocupado_Bench
|
Inactivo_Bench
|
Ocupado
|
Desocupado
|
Inactivo
|
|
01
|
0.5537
|
0.0236
|
0.4227
|
0.5537
|
0.0236
|
0.4227
|
|
02
|
0.5492
|
0.0349
|
0.4159
|
0.5492
|
0.0349
|
0.4159
|
|
03
|
0.5236
|
0.0855
|
0.3909
|
0.5236
|
0.0855
|
0.3909
|
|
04
|
0.5136
|
0.0337
|
0.4526
|
0.5136
|
0.0337
|
0.4526
|
|
05
|
0.4623
|
0.0423
|
0.4954
|
0.4623
|
0.0423
|
0.4954
|
|
06
|
0.4999
|
0.0298
|
0.4703
|
0.4999
|
0.0298
|
0.4703
|
|
07
|
0.5295
|
0.0174
|
0.4532
|
0.5295
|
0.0174
|
0.4532
|
|
08
|
0.5639
|
0.0678
|
0.3683
|
0.5639
|
0.0678
|
0.3683
|
|
09
|
0.5257
|
0.0505
|
0.4238
|
0.5257
|
0.0505
|
0.4238
|
|
10
|
0.5144
|
0.0402
|
0.4453
|
0.5144
|
0.0402
|
0.4453
|
- Guardar resultados
estimaciones <- inner_join(estimaciones,estimacionesBench)
saveRDS(object = estimaciones, file = "Recursos/Día5/Sesion1/Data/estimaciones_Bench.rds")