11.3 Proceso de estimación y predicción
Obtener el modelo es solo un paso más, ahora se debe realizar la predicción en el censo, el cual a sido previamente estandarizado y homologado con la encuesta.
poststrat_df <- readRDS("Recursos/Día4/Sesion1/Data/censo_mrp_dam2.rds") %>%
left_join(statelevel_predictors_df)
tba( poststrat_df %>% arrange(desc(n)) %>% head(10))| dam | dam2 | id_municipio | nombre_region | region | area | sexo | edad | anoest | n | modificacion_humana | accesibilidad_hospitales | accesibilidad_hosp_caminado | cubrimiento_cultivo | cubrimiento_urbano | luces_nocturnas | area1 | sexo2 | edad2 | edad3 | edad4 | edad5 | anoest2 | anoest3 | anoest4 | anoest99 | tiene_sanitario | tiene_acueducto | tiene_gas | eliminar_basura | tiene_internet | piso_tierra | material_paredes | material_techo | rezago_escolar | alfabeta | hacinamiento | tasa_desocupacion |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | 03201 | 103201 | Región Ozama | 10 | 1 | 2 | 2 | 3 | 78858 | 2.7794 | -1.1311 | -1.4114 | -0.3529 | 4.1625 | 3.8009 | 0.9256 | 0.5173 | 0.2869 | 0.2158 | 0.1599 | 0.0502 | 0.2161 | 0.4041 | 0.1677 | 0.0161 | 0.0200 | 0.7131 | 0.0571 | 0.1791 | 0.7701 | 0.0102 | 0.0245 | 0.0153 | 0.2883 | 0.9252 | 0.1870 | 0.0074 |
| 32 | 03201 | 103201 | Región Ozama | 10 | 1 | 1 | 2 | 3 | 77566 | 2.7794 | -1.1311 | -1.4114 | -0.3529 | 4.1625 | 3.8009 | 0.9256 | 0.5173 | 0.2869 | 0.2158 | 0.1599 | 0.0502 | 0.2161 | 0.4041 | 0.1677 | 0.0161 | 0.0200 | 0.7131 | 0.0571 | 0.1791 | 0.7701 | 0.0102 | 0.0245 | 0.0153 | 0.2883 | 0.9252 | 0.1870 | 0.0074 |
| 01 | 00101 | 100101 | Región Ozama | 10 | 1 | 1 | 2 | 3 | 76098 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 | 4.9650 | 1.0000 | 0.5224 | 0.2781 | 0.2117 | 0.1808 | 0.0725 | 0.2000 | 0.3680 | 0.2286 | 0.0193 | 0.0119 | 0.7946 | 0.0673 | 0.0810 | 0.6678 | 0.0033 | 0.0109 | 0.0111 | 0.3694 | 0.9247 | 0.1962 | 0.0066 |
| 01 | 00101 | 100101 | Región Ozama | 10 | 1 | 2 | 2 | 3 | 76002 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 | 4.9650 | 1.0000 | 0.5224 | 0.2781 | 0.2117 | 0.1808 | 0.0725 | 0.2000 | 0.3680 | 0.2286 | 0.0193 | 0.0119 | 0.7946 | 0.0673 | 0.0810 | 0.6678 | 0.0033 | 0.0109 | 0.0111 | 0.3694 | 0.9247 | 0.1962 | 0.0066 |
| 25 | 02501 | 012501 | Región Cibao Norte | 01 | 1 | 2 | 2 | 3 | 52770 | 1.4723 | -0.9237 | -1.0018 | 0.3619 | 1.3166 | 1.6641 | 0.8601 | 0.5084 | 0.2837 | 0.2250 | 0.1564 | 0.0596 | 0.2622 | 0.3832 | 0.1282 | 0.0114 | 0.0189 | 0.8665 | 0.1021 | 0.1307 | 0.7972 | 0.0134 | 0.0136 | 0.0160 | 0.2118 | 0.8939 | 0.1787 | 0.0044 |
| 25 | 02501 | 012501 | Región Cibao Norte | 01 | 1 | 1 | 2 | 3 | 51227 | 1.4723 | -0.9237 | -1.0018 | 0.3619 | 1.3166 | 1.6641 | 0.8601 | 0.5084 | 0.2837 | 0.2250 | 0.1564 | 0.0596 | 0.2622 | 0.3832 | 0.1282 | 0.0114 | 0.0189 | 0.8665 | 0.1021 | 0.1307 | 0.7972 | 0.0134 | 0.0136 | 0.0160 | 0.2118 | 0.8939 | 0.1787 | 0.0044 |
| 32 | 03201 | 103201 | Región Ozama | 10 | 1 | 1 | 1 | 2 | 50744 | 2.7794 | -1.1311 | -1.4114 | -0.3529 | 4.1625 | 3.8009 | 0.9256 | 0.5173 | 0.2869 | 0.2158 | 0.1599 | 0.0502 | 0.2161 | 0.4041 | 0.1677 | 0.0161 | 0.0200 | 0.7131 | 0.0571 | 0.1791 | 0.7701 | 0.0102 | 0.0245 | 0.0153 | 0.2883 | 0.9252 | 0.1870 | 0.0074 |
| 01 | 00101 | 100101 | Región Ozama | 10 | 1 | 1 | 1 | 2 | 50015 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 | 4.9650 | 1.0000 | 0.5224 | 0.2781 | 0.2117 | 0.1808 | 0.0725 | 0.2000 | 0.3680 | 0.2286 | 0.0193 | 0.0119 | 0.7946 | 0.0673 | 0.0810 | 0.6678 | 0.0033 | 0.0109 | 0.0111 | 0.3694 | 0.9247 | 0.1962 | 0.0066 |
| 32 | 03201 | 103201 | Región Ozama | 10 | 1 | 2 | 1 | 2 | 49652 | 2.7794 | -1.1311 | -1.4114 | -0.3529 | 4.1625 | 3.8009 | 0.9256 | 0.5173 | 0.2869 | 0.2158 | 0.1599 | 0.0502 | 0.2161 | 0.4041 | 0.1677 | 0.0161 | 0.0200 | 0.7131 | 0.0571 | 0.1791 | 0.7701 | 0.0102 | 0.0245 | 0.0153 | 0.2883 | 0.9252 | 0.1870 | 0.0074 |
| 01 | 00101 | 100101 | Región Ozama | 10 | 1 | 2 | 1 | 2 | 49010 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 | 4.9650 | 1.0000 | 0.5224 | 0.2781 | 0.2117 | 0.1808 | 0.0725 | 0.2000 | 0.3680 | 0.2286 | 0.0193 | 0.0119 | 0.7946 | 0.0673 | 0.0810 | 0.6678 | 0.0033 | 0.0109 | 0.0111 | 0.3694 | 0.9247 | 0.1962 | 0.0066 |
Note que la información del censo esta agregada.
11.3.1 Distribución posterior.
Para obtener una distribución posterior de cada observación se hace uso de la función posterior_epred de la siguiente forma.
epred_mat <- posterior_epred(fit, newdata = poststrat_df, type = "response")Como el interés es realizar comparaciones entre los países de la región se presenta la estimación del ingreso medio en términos de lineas de pobreza. Para esto procedemos así:
- Obteniendo las lineas de pobreza por cada post-estrato
(lp <- encuesta_mrp %>% distinct(area,lp,li)) %>%
tba()| area | lp | li |
|---|---|---|
| 1 | 5622.81 | 3159.09 |
| 0 | 4876.69 | 3061.23 |
| 1 | 5710.40 | 3193.03 |
| 0 | 4949.12 | 3094.12 |
| 1 | 5844.03 | 3291.64 |
| 0 | 5070.47 | 3189.68 |
| 1 | 5973.59 | 3377.04 |
| 0 | 5185.77 | 3272.42 |
- Ingreso en términos de lineas de pobreza.
lp %<>% group_by(area) %>% summarise(lp = mean(lp),li = mean(li))
lp <- inner_join(poststrat_df,lp,by = "area") %>% select(lp)
epred_mat <- (exp(epred_mat)-1)/lp$lp11.3.2 Estimación del ingreso medio nacional
n_filtered <- poststrat_df$n
mrp_estimates <- epred_mat %*% n_filtered / sum(n_filtered)
(temp_ing <- data.frame(
mrp_estimate = mean(mrp_estimates),
mrp_estimate_se = sd(mrp_estimates)
) ) %>% tba()| mrp_estimate | mrp_estimate_se |
|---|---|
| 1.6535 | 0.0052 |
El resultado nos indica que el ingreso medio nacional es 1.65 lineas de pobreza
11.3.3 Estimación para el dam == “01”.
Es importante siempre conservar el orden de la base, dado que relación entre la predicción y el censo en uno a uno.
temp <- poststrat_df %>% mutate(Posi = 1:n())
temp <- filter(temp, dam == "01") %>% select(n, Posi)
n_filtered <- temp$n
temp_epred_mat <- epred_mat[, temp$Posi]
## Estimando el CME
mrp_estimates <- temp_epred_mat %*% n_filtered / sum(n_filtered)
(temp_dam11 <- data.frame(
mrp_estimate = mean(mrp_estimates),
mrp_estimate_se = sd(mrp_estimates)
) ) %>% tba()| mrp_estimate | mrp_estimate_se |
|---|---|
| 1.6709 | 0.0159 |
El resultado nos indica que el ingreso medio en el dam 01 es 1.67 lineas de pobreza
11.3.4 Estimación para la dam2 == “00203”
temp <- poststrat_df %>% mutate(Posi = 1:n())
temp <-
filter(temp, dam2 == "00203") %>% select(n, Posi)
n_filtered <- temp$n
temp_epred_mat <- epred_mat[, temp$Posi]
## Estimando el CME
mrp_estimates <- temp_epred_mat %*% n_filtered / sum(n_filtered)
(temp_dam2_00203 <- data.frame(
mrp_estimate = mean(mrp_estimates),
mrp_estimate_se = sd(mrp_estimates)
) ) %>% tba()| mrp_estimate | mrp_estimate_se |
|---|---|
| 1.2141 | 0.0394 |
El resultado nos indica que el ingreso medio en la dam2 00203 es 1.21 lineas de pobreza
Después de comprender la forma en que se realiza la estimación de los dominios no observados procedemos el uso de la función Aux_Agregado que es desarrollada para este fin.
(mrp_estimate_Ingresolp <-
Aux_Agregado(poststrat = poststrat_df,
epredmat = epred_mat,
byMap = NULL)
) %>% tba()| Nacional | mrp_estimate | mrp_estimate_se |
|---|---|---|
| Nacional | 1.6535 | 0.0052 |
El resultado nos indica que el ingreso medio nacional es 2 lineas de pobreza
De forma similar es posible obtener los resultados para las divisiones administrativas.
mrp_estimate_dam <-
Aux_Agregado(poststrat = poststrat_df,
epredmat = epred_mat,
byMap = "dam")
tba(mrp_estimate_dam %>% head(10) )| dam | mrp_estimate | mrp_estimate_se |
|---|---|---|
| 01 | 1.6709 | 0.0159 |
| 02 | 1.5548 | 0.0340 |
| 03 | 1.1277 | 0.0122 |
| 04 | 1.4136 | 0.0211 |
| 05 | 1.5726 | 0.0460 |
| 06 | 1.6536 | 0.0229 |
| 07 | 1.1500 | 0.0421 |
| 08 | 1.7535 | 0.0258 |
| 09 | 1.9046 | 0.0248 |
| 10 | 1.1804 | 0.0385 |
mrp_estimate_dam2 <-
Aux_Agregado(poststrat = poststrat_df,
epredmat = epred_mat,
byMap = "dam2")
tba(mrp_estimate_dam2 %>% head(10) )| dam2 | mrp_estimate | mrp_estimate_se |
|---|---|---|
| 00101 | 1.6709 | 0.0159 |
| 00201 | 1.6356 | 0.0339 |
| 00202 | 1.2880 | 0.0418 |
| 00203 | 1.2141 | 0.0394 |
| 00204 | 2.0706 | 0.0991 |
| 00205 | 1.2337 | 0.0582 |
| 00206 | 1.3713 | 0.0429 |
| 00207 | 1.5580 | 0.3652 |
| 00208 | 1.4348 | 0.0501 |
| 00209 | 1.4726 | 0.3456 |
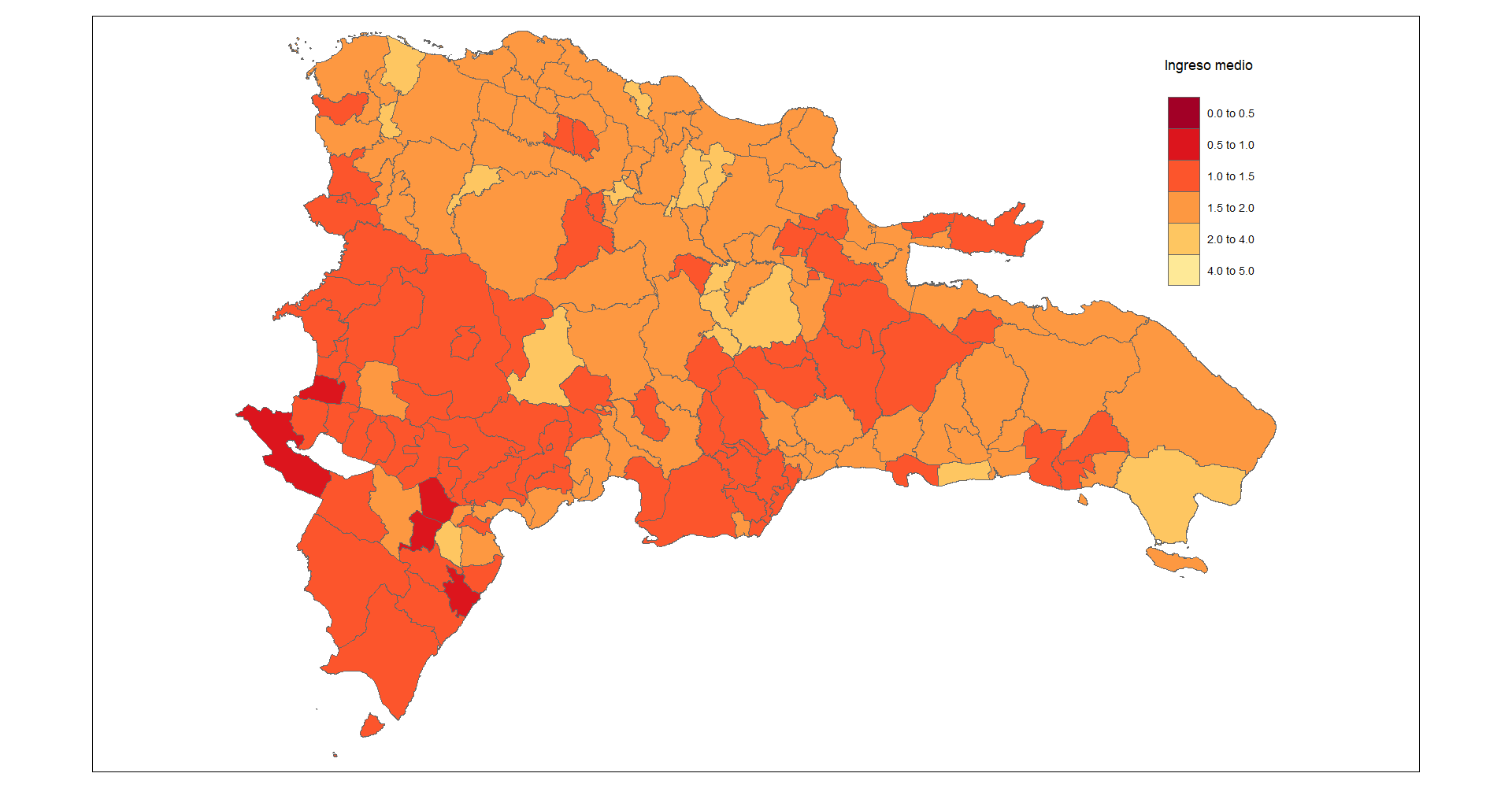
El mapa resultante es el siguiente