12.2 Proceso de estimación en R
Para desarrollar la metodología se hace uso de las siguientes librerías.
# Interprete de STAN en R
library(rstan)
library(rstanarm)
# Manejo de bases de datos.
library(tidyverse)
# Gráficas de los modelos.
library(bayesplot)
library(patchwork)
# Organizar la presentación de las tablas
library(kableExtra)
library(printr)Un conjunto de funciones desarrolladas para realizar de forma simplificada los procesos están consignadas en la siguiente rutina.
source("Recursos/Día4/Sesion2/0Recursos/funciones_mrp.R")Entre las funciones incluidas en el archivo encuentra
plot_interaction: Esta crea un diagrama de lineas donde se estudia la interacción entre las variables, en el caso de presentar un traslape de las lineas se recomienda incluir el interacción en el modelo.
Plot_Compare Puesto que es necesario realizar una homologar la información del censo y la encuesta es conveniente llevar a cabo una validación de las variables que han sido homologadas, por tanto, se espera que las proporciones resultantes del censo y la encuesta estén cercanas entre sí.
Aux_Agregado: Esta es función permite obtener estimaciones a diferentes niveles de agregación, toma mucha relevancia cuando se realiza un proceso repetitivo.
Las funciones están diseñada específicamente para este proceso
12.2.1 Encuesta de hogares
Los datos empleados en esta ocasión corresponden a la ultima encuesta de hogares, la cual ha sido estandarizada por CEPAL y se encuentra disponible en BADEHOG
encuesta <- readRDS("Recursos/Día4/Sesion2/Data/encuestaDOM21N1.rds")
encuesta_mrp <- encuesta %>%
transmute(
dam = haven::as_factor(dam_ee,levels = "values"),
dam = str_pad(string = dam, width = 2, pad = "0"),
dam2,
ingreso = ingcorte, lp, li,
area = haven::as_factor(area_ee,levels = "values"),
area = case_when(area == 1 ~ "1", TRUE ~ "0"),
pobreza = ifelse(ingcorte < lp,1,0),
sexo = as.character(sexo),
anoest = case_when(
edad < 5 | anoest == -1 | is.na(anoest) ~ "98" , #No aplica
anoest == 99 ~ "99", #NS/NR
anoest == 0 ~ "1", # Sin educacion
anoest %in% c(1:6) ~ "2", # 1 - 6
anoest %in% c(7:12) ~ "3", # 7 - 12
anoest > 12 ~ "4", # mas de 12
TRUE ~ "Error" ),
edad = case_when(
edad < 15 ~ "1",
edad < 30 ~ "2",
edad < 45 ~ "3",
edad < 65 ~ "4",
TRUE ~ "5"),
fep = `_fep`
)
tba(encuesta_mrp %>% head(10)) | dam | dam2 | ingreso | lp | li | area | pobreza | sexo | anoest | edad | fep |
|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 00101 | 54000.00 | 5622.81 | 3159.09 | 1 | 0 | 1 | 4 | 3 | 137.0652 |
| 01 | 00101 | 16388.89 | 5622.81 | 3159.09 | 1 | 0 | 2 | 3 | 4 | 137.0652 |
| 01 | 00101 | 16388.89 | 5622.81 | 3159.09 | 1 | 0 | 1 | 3 | 5 | 137.0652 |
| 01 | 00101 | 16388.89 | 5622.81 | 3159.09 | 1 | 0 | 1 | 4 | 2 | 137.0652 |
| 01 | 00101 | 6224.00 | 5622.81 | 3159.09 | 1 | 0 | 2 | 2 | 4 | 137.0652 |
| 01 | 00101 | 6224.00 | 5622.81 | 3159.09 | 1 | 0 | 1 | 3 | 3 | 137.0652 |
| 01 | 00101 | 6224.00 | 5622.81 | 3159.09 | 1 | 0 | 2 | 4 | 2 | 137.0652 |
| 01 | 00101 | 20672.00 | 5622.81 | 3159.09 | 1 | 0 | 2 | 1 | 5 | 137.0652 |
| 01 | 00101 | 8495.60 | 5622.81 | 3159.09 | 1 | 0 | 1 | 4 | 3 | 137.0652 |
| 01 | 00101 | 8495.60 | 5622.81 | 3159.09 | 1 | 0 | 2 | 3 | 3 | 137.0652 |
La base de datos de la encuesta tiene la siguientes columnas:
dam: Corresponde al código asignado a la división administrativa mayor del país.
dam2: Corresponde al código asignado a la segunda división administrativa del país.
lp y li lineas de pobreza y pobreza extrema definidas por CEPAL.
área división geográfica (Urbano y Rural).
sexo Hombre y Mujer.
etnia En estas variable se definen tres grupos: afrodescendientes, indígenas y Otros.
Años de escolaridad (anoest)
Rangos de edad (edad)
Factor de expansión por persona (fep)
Ahora, inspeccionamos el comportamiento de la variable de interés:
tab <- encuesta_mrp %>% group_by(pobreza) %>%
tally() %>%
mutate(prop = round(n/sum(n),2),
pobreza = ifelse(pobreza == 1, "Si", "No"))
ggplot(data = tab, aes(x = pobreza, y = prop)) +
geom_bar(stat = "identity") +
labs(y = "", x = "") +
geom_text(aes(label = paste(prop*100,"%")),
nudge_y=0.05) +
theme_bw(base_size = 20) +
theme(axis.text.y = element_blank(),
axis.ticks = element_blank())
Figura 12.1: Proporción de personas por debajo de la linea de pobreza
La información auxiliar disponible ha sido extraída del censo e imágenes satelitales
statelevel_predictors_df <-
readRDS("Recursos/Día4/Sesion2/Data/statelevel_predictors_df_dam2.rds") %>%
mutate_at(.vars = c("luces_nocturnas",
"cubrimiento_cultivo",
"cubrimiento_urbano",
"modificacion_humana",
"accesibilidad_hospitales",
"accesibilidad_hosp_caminado"),
function(x) as.numeric(scale(x)))
tba(statelevel_predictors_df %>% head(10))| dam2 | modificacion_humana | accesibilidad_hospitales | accesibilidad_hosp_caminado | cubrimiento_cultivo | cubrimiento_urbano | luces_nocturnas | area1 | sexo2 | edad2 | edad3 | edad4 | edad5 | anoest2 | anoest3 | anoest4 | anoest99 | tiene_sanitario | tiene_acueducto | tiene_gas | eliminar_basura | tiene_internet | piso_tierra | material_paredes | material_techo | rezago_escolar | alfabeta | hacinamiento | tasa_desocupacion | id_municipio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 00101 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 | 4.9650 | 1.0000 | 0.5224 | 0.2781 | 0.2117 | 0.1808 | 0.0725 | 0.2000 | 0.3680 | 0.2286 | 0.0193 | 0.0119 | 0.7946 | 0.0673 | 0.0810 | 0.6678 | 0.0033 | 0.0109 | 0.0111 | 0.3694 | 0.9247 | 0.1962 | 0.0066 | 100101 |
| 00201 | -0.0553 | 0.4449 | 0.2100 | 0.0684 | -0.0682 | -0.1511 | 0.8904 | 0.4933 | 0.2726 | 0.1849 | 0.1520 | 0.0614 | 0.3149 | 0.3022 | 0.0775 | 0.0082 | 0.1005 | 0.7220 | 0.2261 | 0.1300 | 0.9276 | 0.0664 | 0.0812 | 0.0249 | 0.1501 | 0.7975 | 0.3014 | 0.0007 | 050201 |
| 00202 | -0.3758 | 0.0000 | 0.1482 | -0.2345 | -0.2855 | -0.4234 | 0.6799 | 0.4697 | 0.2804 | 0.1895 | 0.1430 | 0.0515 | 0.3757 | 0.2405 | 0.0148 | 0.0014 | 0.1322 | 0.9230 | 0.2693 | 0.2884 | 0.9759 | 0.0625 | 0.0986 | 0.0673 | 0.0278 | 0.7140 | 0.3454 | 0.0001 | 050202 |
| 00203 | -0.9259 | 0.5732 | -0.1402 | -0.5511 | -0.3822 | -0.5612 | 0.5814 | 0.4601 | 0.2665 | 0.1733 | 0.1586 | 0.0713 | 0.3778 | 0.2463 | 0.0219 | 0.0052 | 0.2579 | 0.7602 | 0.4824 | 0.2589 | 0.9919 | 0.1937 | 0.2342 | 0.1238 | 0.0485 | 0.7104 | 0.2755 | 0.0001 | 050203 |
| 00204 | -1.3166 | 1.1111 | 0.4438 | -0.5027 | -0.3835 | -0.6042 | 0.5708 | 0.4663 | 0.2647 | 0.1683 | 0.1673 | 0.0757 | 0.3306 | 0.2402 | 0.0440 | 0.0049 | 0.1672 | 0.6375 | 0.5040 | 0.3837 | 0.9759 | 0.1403 | 0.1354 | 0.0176 | 0.0873 | 0.6737 | 0.2671 | 0.0002 | 050204 |
| 00205 | -0.7474 | 2.1155 | 1.2271 | -0.5838 | -0.3345 | -0.5909 | 0.6937 | 0.4633 | 0.2849 | 0.2107 | 0.1473 | 0.0583 | 0.2794 | 0.2821 | 0.0562 | 0.0067 | 0.3800 | 0.6596 | 0.5014 | 0.2852 | 0.9894 | 0.2309 | 0.2498 | 0.0459 | 0.1016 | 0.6751 | 0.4973 | 0.0001 | 050205 |
| 00206 | 0.5157 | -0.1468 | -0.1811 | 1.1894 | -0.1191 | -0.4022 | 0.9563 | 0.4557 | 0.2910 | 0.1814 | 0.1495 | 0.0626 | 0.3793 | 0.2815 | 0.0427 | 0.0052 | 0.1301 | 0.8817 | 0.2565 | 0.1495 | 0.9659 | 0.0629 | 0.0472 | 0.0337 | 0.0835 | 0.8027 | 0.2200 | 0.0001 | 050206 |
| 00207 | 1.7368 | -0.7648 | -0.4861 | 0.7170 | -0.0609 | 0.0042 | 0.5201 | 0.4783 | 0.2898 | 0.1675 | 0.1464 | 0.0531 | 0.3552 | 0.2901 | 0.0328 | 0.0061 | 0.2434 | 0.5775 | 0.2758 | 0.0950 | 0.9911 | 0.0717 | 0.2004 | 0.1304 | 0.0714 | 0.7778 | 0.3936 | 0.0001 | 050207 |
| 00208 | -0.5942 | 0.3212 | -0.1697 | -0.3627 | -0.3044 | -0.4750 | 0.6625 | 0.4334 | 0.2943 | 0.1875 | 0.1523 | 0.0654 | 0.3557 | 0.2486 | 0.0250 | 0.0054 | 0.1908 | 0.8251 | 0.4152 | 0.1450 | 0.9907 | 0.1458 | 0.1517 | 0.0852 | 0.0509 | 0.6897 | 0.3051 | 0.0001 | 050208 |
| 00209 | -1.5280 | 3.0192 | 1.9428 | -0.8078 | -0.4046 | -0.6423 | 0.6798 | 0.4311 | 0.2858 | 0.1687 | 0.1628 | 0.0701 | 0.3648 | 0.2645 | 0.0752 | 0.0061 | 0.1893 | 0.5760 | 0.4096 | 0.3557 | 0.9978 | 0.1097 | 0.0941 | 0.0292 | 0.1357 | 0.7680 | 0.2189 | 0.0001 | 050209 |
12.2.2 Niveles de agregación para colapsar la encuesta
Después de realizar una investigación en la literatura especializada y realizar estudios de simulación fue posible evidenciar que las predicciones obtenidas con la muestra sin agregar y la muestra agregada convergen a la media del dominio.
byAgrega <- c("dam", "dam2", "area",
"sexo", "anoest", "edad" )12.2.3 Creando base con la encuesta agregada
El resultado de agregar la base de dato se muestra a continuación:
encuesta_df_agg <-
encuesta_mrp %>% # Encuesta
group_by_at(all_of(byAgrega)) %>% # Agrupar por el listado de variables
summarise(n = n(), # Número de observaciones
# conteo de personas con características similares.
pobreza = sum(pobreza),
no_pobreza = n-pobreza,
.groups = "drop") %>%
arrange(desc(pobreza)) # Ordenar la base.La tabla obtenida es la siguiente:
| dam | dam2 | area | sexo | anoest | edad | n | pobreza | no_pobreza |
|---|---|---|---|---|---|---|---|---|
| 01 | 00101 | 1 | 2 | 3 | 2 | 624 | 221 | 403 |
| 32 | 03201 | 1 | 2 | 2 | 1 | 359 | 158 | 201 |
| 01 | 00101 | 1 | 1 | 2 | 1 | 401 | 155 | 246 |
| 32 | 03201 | 1 | 2 | 3 | 2 | 576 | 154 | 422 |
| 01 | 00101 | 1 | 2 | 2 | 1 | 348 | 148 | 200 |
| 32 | 03201 | 1 | 1 | 2 | 1 | 369 | 145 | 224 |
| 01 | 00101 | 1 | 1 | 3 | 2 | 652 | 135 | 517 |
| 32 | 03203 | 1 | 2 | 3 | 2 | 393 | 128 | 265 |
| 01 | 00101 | 1 | 1 | 98 | 1 | 302 | 127 | 175 |
| 25 | 02501 | 1 | 2 | 3 | 2 | 447 | 126 | 321 |
El paso a seguir es unificar las tablas creadas.
encuesta_df_agg <- inner_join(encuesta_df_agg, statelevel_predictors_df)12.2.4 Definiendo el modelo multinivel.
Después de haber ordenado la encuesta, podemos pasar a la definición del modelo.
options(mc.cores = parallel::detectCores()) # Permite procesar en paralelo.
fit <- stan_glmer(
cbind(pobreza, no_pobreza) ~
(1 | dam2) + # Efecto aleatorio (ud)
edad + # Efecto fijo (Variables X)
sexo +
tasa_desocupacion +
luces_nocturnas +
cubrimiento_cultivo +
cubrimiento_urbano ,
data = encuesta_df_agg, # Encuesta agregada
verbose = TRUE, # Muestre el avance del proceso
chains = 4, # Número de cadenas.
iter = 1000, # Número de realizaciones de la cadena
cores = 4,
family = binomial(link = "logit")
)
saveRDS(fit, file = "Recursos/Día4/Sesion2/Data/fit_pobreza.rds")Después de esperar un tiempo prudente se obtiene el siguiente modelo.
fit <- readRDS("Recursos/Día4/Sesion2/Data/fit_pobreza.rds")Validación del modelo
library(posterior)
library(bayesplot)
var_names <- c("edad2", "edad3", "edad4", "edad5", "sexo2",
"luces_nocturnas", "cubrimiento_cultivo","cubrimiento_urbano")
mcmc_areas(fit,pars = var_names)
mcmc_trace(fit,pars = var_names)
encuesta_mrp2 <- inner_join(encuesta_mrp, statelevel_predictors_df)
y_pred_B <- posterior_epred(fit, newdata = encuesta_mrp2)
rowsrandom <- sample(nrow(y_pred_B), 100)
y_pred2 <- y_pred_B[rowsrandom, ]
ppc_dens_overlay(y = as.numeric(encuesta_mrp2$pobreza), y_pred2) 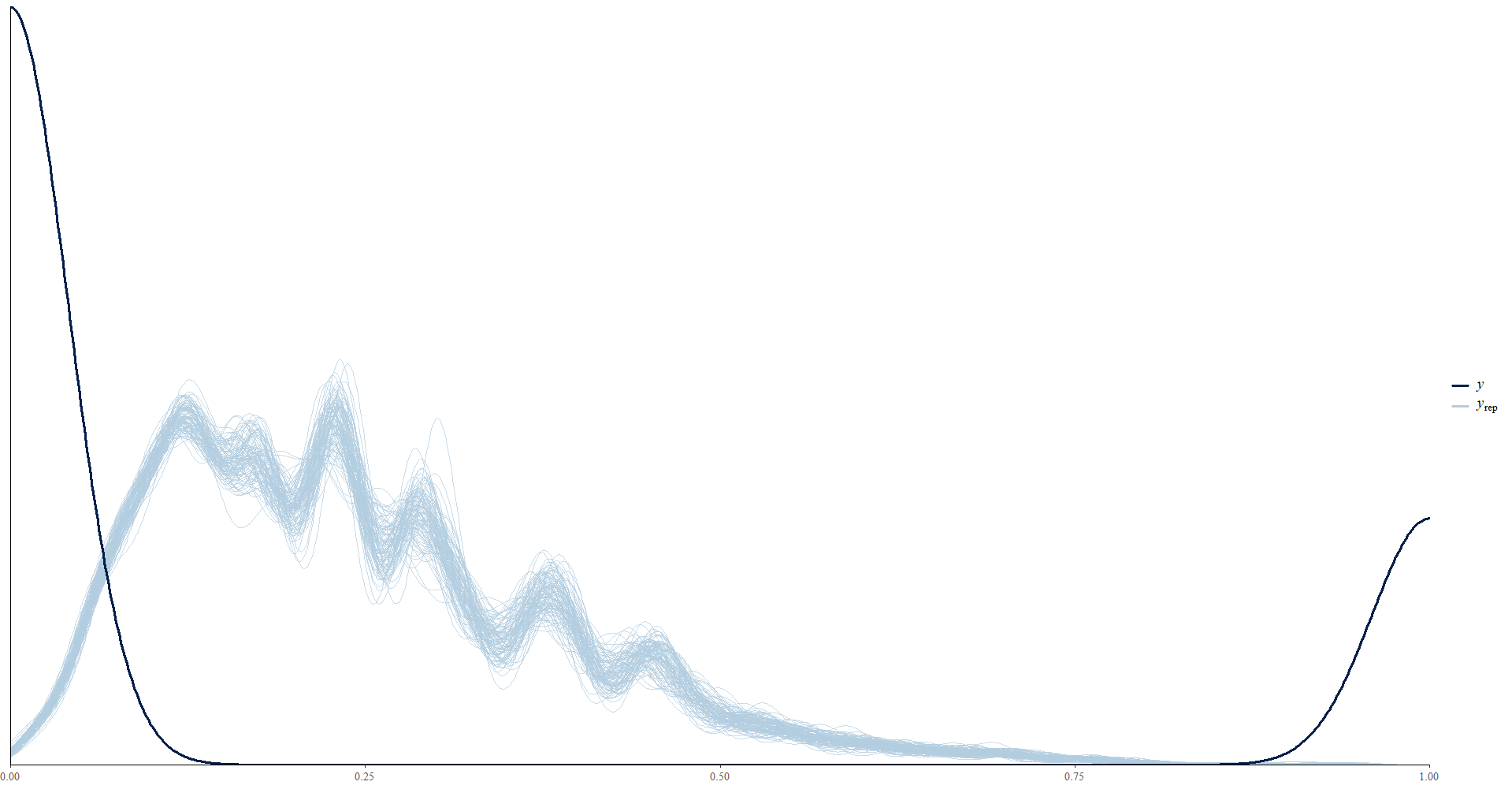
Figura 12.2: Tasa de pobreza por dam2
Los coeficientes del modelo para las primeras dam2 son:
| (Intercept) | edad2 | edad3 | edad4 | edad5 | sexo2 | tasa_desocupacion | luces_nocturnas | cubrimiento_cultivo | cubrimiento_urbano | |
|---|---|---|---|---|---|---|---|---|---|---|
| 00101 | -0.7843 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00201 | -0.8704 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00202 | -0.5086 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00203 | -0.2080 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00204 | -0.9745 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00205 | -0.5200 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00206 | -0.1536 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00208 | -0.4769 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00210 | -1.3939 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |
| 00301 | 0.2809 | -0.7164 | -0.7355 | -1.5045 | -1.6397 | 0.2901 | 8.0861 | -0.2643 | -0.0691 | 0.197 |