9.2 Modelo Fay Herriot de variable respuesta beta.
El modelo lineal de Fay-Herriot puede ser reemplazado por un modelo mixto lineal generalizado (GLMM). Esto se puede hacer cuando los datos observados \(Y_d\) son inherentemente discretos, como cuando son recuentos (no ponderados) de personas u hogares muestreados con ciertas características. Uno de estos modelos supone una distribución binomial para \(Y_d\) con probabilidad de éxito \(\theta_d\), y una logística modelo de regresión para \(\theta_d\) con errores normales en la escala logit. El modelo resultante es
\[ \begin{eqnarray*} Y_{d}\mid \theta_{d},n_{d} & \sim & Bin\left(n_{d},\theta_{d}\right) \end{eqnarray*} \] para \(d=1,\dots,D\) y
\[ \begin{eqnarray*} logit\left(\theta_{d}\right)=\log\left(\frac{\theta_{d}}{1-\theta_{d}}\right) & = & \boldsymbol{x}_{d}^{T}\boldsymbol{\beta}+u_{d} \end{eqnarray*} \] donde \(u_{d}\sim N\left(0,\sigma_{u}^{2}\right)\) y \(n_{d}\) es el tamaño de la muestra para el área \(d\).
El modelo anterior se puede aplicar fácilmente a recuentos de muestras no ponderadas \(Y_d\), pero esto ignora cualquier aspecto complejo del diseño de la encuesta. En muestras complejas donde las \(Y_d\) son estimaciones ponderadas, surgen dos problemas. En primer lugar, los posibles valores de el \(Y_d\) no serán los números enteros \(0, 1, \dots , n_d\) para cualquier definición directa de tamaño de muestra \(n_d\). En su lugar, \(Y_d\) tomará un valor de un conjunto finito de números desigualmente espaciados determinados por las ponderaciones de la encuesta que se aplican a los casos de muestra en el dominio \(d\). En segundo lugar, la varianza muestral de \(Y_d\) implícito en la distribución Binomial, es decir, \(n_d \times \theta_d (1-\theta_d)\), será incorrecto. Abordamos estos dos problemas al definir un tamaño de muestra efectivo \(\tilde{n}_d\), y un número de muestra efectivo de éxitos \(\tilde{Y_d}\) determinó mantener: (i) la estimación directa \(\hat{\theta}_i\), de la pobreza y (ii) una estimación de la varianza de muestreo correspondiente,\(\widehat{Var}(\hat{\theta}_d)\).
Es posible suponer que \[ \begin{eqnarray*} \tilde{n}_{d} & \sim & \frac{\check{\theta}_{d}\left(1-\check{\theta}_{d}\right)}{\widehat{Var}\left(\hat{\theta}_{d}\right)} \end{eqnarray*} \] donde \(\check{\theta}_{d}\) es una preliminar perdicción basada en el modelo para la proporción poblacional \(\theta_d\) y \(\widehat{Var}\left(\hat{\theta}_{d}\right)\) depende de\(\check{\theta}_{d}\) a través de una función de varianza generalizada ajustada (FGV). Note que \(\tilde{Y}_{d}=\tilde{n}_{d}\times\hat{\theta}_{d}\).
Suponga de las distribuciones previas para \(\boldsymbol{\beta}\) y \(\sigma_{u}^{2}\) son dadas por \[ \begin{eqnarray*} \boldsymbol{\beta} \sim N\left(0,10000\right)\\ \sigma_{u}^{2} \sim IG\left(0.0001,0.0001\right) \end{eqnarray*} \]
9.2.1 Procedimiento de estimación
Lectura de la base de datos que resultó en el paso anterior y selección de las columnas de interés
library(tidyverse)
library(magrittr)
base_FH <- readRDS("Recursos/Día3/Sesion2/Data/base_FH_2018.rds") %>%
select(dam2, pobreza, n_eff_FGV)Lectura de las covariables, las cuales son obtenidas previamente. Dado la diferencia entre las escalas de las variables es necesario hacer un ajuste a estas.
statelevel_predictors_df <- readRDS("Recursos/Día3/Sesion2/Data/statelevel_predictors_df_dam2.rds") %>%
mutate_at(.vars = c("luces_nocturnas",
"cubrimiento_cultivo",
"cubrimiento_urbano",
"modificacion_humana",
"accesibilidad_hospitales",
"accesibilidad_hosp_caminado"),
function(x) as.numeric(scale(x)))Uniendo las dos bases de datos.
base_FH <- full_join(base_FH,statelevel_predictors_df, by = "dam2" )
tba(base_FH[,1:8] %>% head(10))| dam2 | pobreza | n_eff_FGV | modificacion_humana | accesibilidad_hospitales | accesibilidad_hosp_caminado | cubrimiento_cultivo | cubrimiento_urbano |
|---|---|---|---|---|---|---|---|
| 00101 | 0.2225 | 332.3384 | 3.6127 | -1.1835 | -1.5653 | -1.1560 | 7.2782 |
| 00201 | 0.1822 | 28.0165 | -0.0553 | 0.4449 | 0.2100 | 0.0684 | -0.0682 |
| 00206 | 0.3366 | 44.7971 | 0.5157 | -0.1468 | -0.1811 | 1.1894 | -0.1191 |
| 00301 | 0.4266 | 125.6580 | 0.1364 | 0.5744 | 1.1660 | 0.2836 | -0.1721 |
| 00302 | 0.4461 | 261.0000 | -0.5103 | 0.2531 | 1.0880 | -0.5047 | -0.3326 |
| 00303 | 0.5587 | 75.7938 | -0.6591 | 0.6249 | 1.2229 | 0.1100 | -0.3174 |
| 00304 | 0.5406 | 154.4069 | -0.5573 | 1.4586 | 2.7337 | -0.8314 | -0.2399 |
| 00401 | 0.3359 | 105.4750 | 0.3979 | -0.0833 | -0.4490 | -0.7770 | 0.1784 |
| 00402 | 0.1496 | 59.6357 | -0.3661 | -0.0114 | -0.2863 | -0.5372 | -0.2723 |
| 00403 | 0.4644 | 197.2378 | -1.0446 | 0.4542 | 0.5702 | -0.4029 | -0.4017 |
Seleccionando las covariables para el modelo.
names_cov <- c(
"sexo2" ,
"anoest2" ,
"anoest3",
"anoest4",
"edad2" ,
"edad3" ,
"edad4" ,
"edad5" ,
"tasa_desocupacion" ,
"luces_nocturnas" ,
"cubrimiento_cultivo" ,
"alfabeta"
)9.2.2 Preparando los insumos para STAN
- Dividir la base de datos en dominios observados y no observados
Dominios observados.
data_dir <- base_FH %>% filter(!is.na(pobreza))Dominios NO observados.
data_syn <-
base_FH %>% anti_join(data_dir %>% select(dam2))
tba(data_syn[1:10,1:8])| dam2 | pobreza | n_eff_FGV | modificacion_humana | accesibilidad_hospitales | accesibilidad_hosp_caminado | cubrimiento_cultivo | cubrimiento_urbano |
|---|---|---|---|---|---|---|---|
| 00202 | NA | NA | -0.3758 | 0.0000 | 0.1482 | -0.2345 | -0.2855 |
| 00203 | NA | NA | -0.9259 | 0.5732 | -0.1402 | -0.5511 | -0.3822 |
| 00204 | NA | NA | -1.3166 | 1.1111 | 0.4438 | -0.5027 | -0.3835 |
| 00205 | NA | NA | -0.7474 | 2.1155 | 1.2271 | -0.5838 | -0.3345 |
| 00207 | NA | NA | 1.7368 | -0.7648 | -0.4861 | 0.7170 | -0.0609 |
| 00208 | NA | NA | -0.5942 | 0.3212 | -0.1697 | -0.3627 | -0.3044 |
| 00209 | NA | NA | -1.5280 | 3.0192 | 1.9428 | -0.8078 | -0.4046 |
| 00210 | NA | NA | -1.0038 | 0.5778 | 0.2678 | -0.4900 | -0.3898 |
| 00305 | NA | NA | -0.8480 | 1.5047 | 3.2004 | -0.8621 | -0.3140 |
| 00404 | NA | NA | -0.5678 | 1.0735 | 0.9856 | -1.1497 | -0.3840 |
- Definir matriz de efectos fijos.
## Dominios observados
Xdat <- data_dir[,names_cov]
## Dominios no observados
Xs <- data_syn[,names_cov]- Obteniendo el tamaño de muestra efectivo \(\tilde{n}_d\), y el número de muestra efectivo de éxitos \(\tilde{Y_d}\)
n_effec = round(data_dir$n_eff_FGV)
y_effect = round((data_dir$pobreza)*n_effec)- Creando lista de parámetros para
STAN
sample_data <- list(
N1 = nrow(Xdat), # Observados.
N2 = nrow(Xs), # NO Observados.
p = ncol(Xdat), # Número de regresores.
X = as.matrix(Xdat), # Covariables Observados.
Xs = as.matrix(Xs), # Covariables NO Observados
n_effec = n_effec,
y_effect = y_effect # Estimación directa.
)- Compilando el modelo en
STAN
library(rstan)
fit_FH_binomial <- "Recursos/Día3/Sesion2/Data/modelosStan/14FH_binomial.stan"
options(mc.cores = parallel::detectCores())
model_FH_Binomial <- stan(
file = fit_FH_binomial,
data = sample_data,
verbose = FALSE,
warmup = 500,
iter = 1000,
cores = 4
)
saveRDS(model_FH_Binomial, file = "Recursos/Día3/Sesion2/Data/model_FH_Binomial.rds")Leer el modelo
model_FH_Binomial <- readRDS("Recursos/Día3/Sesion2/Data/model_FH_Binomial.rds")9.2.2.1 Resultados del modelo para los dominios observados.
En este código, se cargan las librerías bayesplot, posterior y patchwork, que se utilizan para realizar gráficos y visualizaciones de los resultados del modelo.
A continuación, se utiliza la función as.array() y as_draws_matrix() para extraer las muestras de la distribución posterior del parámetro theta del modelo, y se seleccionan aleatoriamente 100 filas de estas muestras utilizando la función sample(), lo que resulta en la matriz y_pred2.
Finalmente, se utiliza la función ppc_dens_overlay() de bayesplot para graficar una comparación entre la distribución empírica de la variable observada pobreza en los datos (data_dir$pobreza) y las distribuciones predictivas posteriores simuladas para la misma variable (y_pred2). La función ppc_dens_overlay() produce un gráfico de densidad para ambas distribuciones, lo que permite visualizar cómo se comparan.
library(bayesplot)
library(patchwork)
library(posterior)
y_pred_B <- as.array(model_FH_Binomial, pars = "theta") %>%
as_draws_matrix()
rowsrandom <- sample(nrow(y_pred_B), 100)
y_pred2 <- y_pred_B[rowsrandom, ]
ppc_dens_overlay(y = as.numeric(data_dir$pobreza), y_pred2)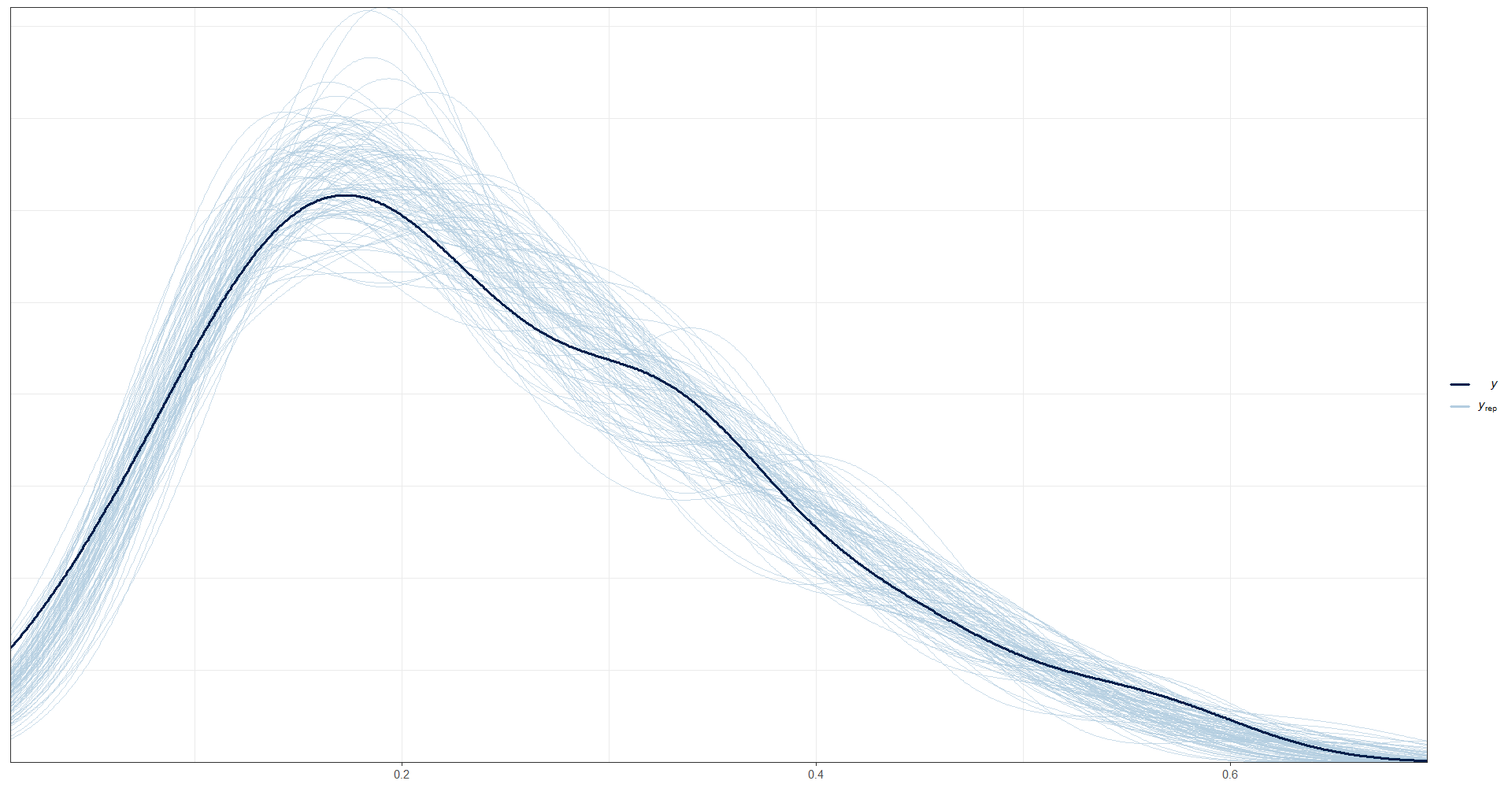
Análisis gráfico de la convergencia de las cadenas de \(\sigma_u\).
posterior_sigma_u <- as.array(model_FH_Binomial, pars = "sigma_u")
(mcmc_dens_chains(posterior_sigma_u) +
mcmc_areas(posterior_sigma_u) ) /
mcmc_trace(posterior_sigma_u)
# traceplot(model_FH_Binomial,pars = "sigma_u",inc_warmup = TRUE)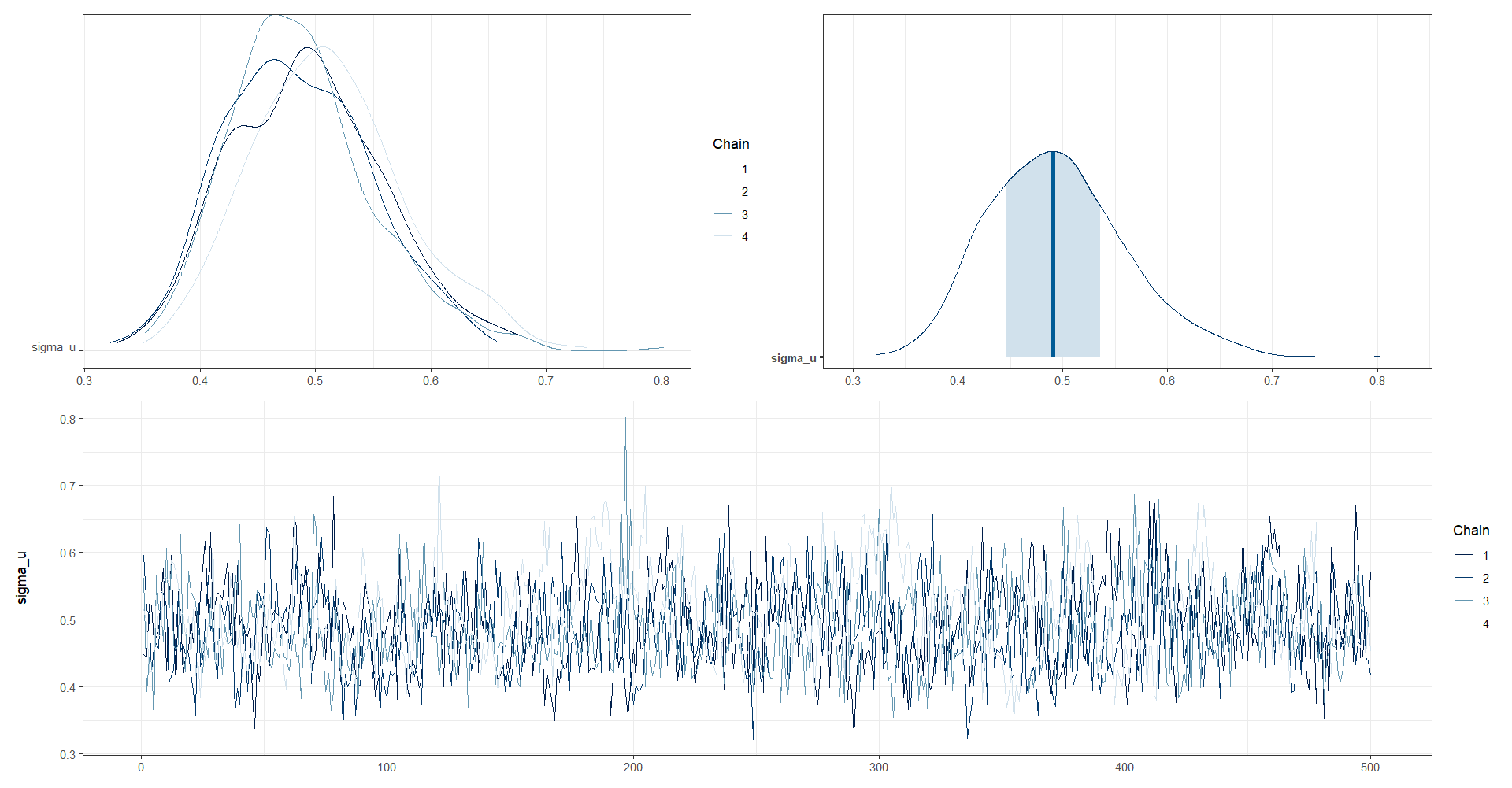
Estimación del FH de la pobreza en los dominios observados.
theta_FH <- summary(model_FH_Binomial,pars = "theta")$summary %>%
data.frame()
data_dir %<>% mutate(pred_binomial = theta_FH$mean,
pred_binomial_EE = theta_FH$sd,
Cv_pred = pred_binomial_EE/pred_binomial)Estimación del FH de la pobreza en los dominios NO observados.
theta_FH_pred <- summary(model_FH_Binomial,pars = "thetaLP")$summary %>%
data.frame()
data_syn <- data_syn %>%
mutate(pred_binomial = theta_FH_pred$mean,
pred_binomial_EE = theta_FH_pred$sd,
Cv_pred = pred_binomial_EE/pred_binomial)9.2.2.2 Mapa de pobreza
El mapa muestra el nivel de pobreza en diferentes áreas de Colombia, basado en dos variables, pobreza y pred_binomial.
Primero, se cargan los paquetes necesarios sp, sf y tmap. Luego, se lee la información de los datos en R y se combinan utilizando la función rbind().
library(sp)
library(sf)
library(tmap)
data_map <- rbind(data_dir, data_syn) %>%
select(dam2, pobreza, pred_binomial, pred_binomial_EE,Cv_pred )
## Leer Shapefile del país
ShapeSAE <- read_sf("Recursos/Día3/Sesion2/Shape/DOM_dam2.shp") %>%
rename(dam2 = id_dominio) %>%
mutate(dam2 = str_pad(
string = dam2,
width = 5,
pad = "0"
))
mapa <- tm_shape(ShapeSAE %>%
left_join(data_map, by = "dam2"))
brks_lp <- c(0,0.15, 0.3, 0.45, 0.6, 1)
tmap_options(check.and.fix = TRUE)
Mapa_lp <-
mapa + tm_polygons(
c("pobreza", "pred_binomial"),
breaks = brks_lp,
title = "Mapa de pobreza",
palette = "YlOrRd",
colorNA = "white"
) + tm_layout(asp = 2.5)
tmap_save(
Mapa_lp,
"Recursos/Día3/Sesion2/0Recursos/Binomial3.PNG",
width = 3000,
height = 2000,
asp = 0
)
Mapa_lp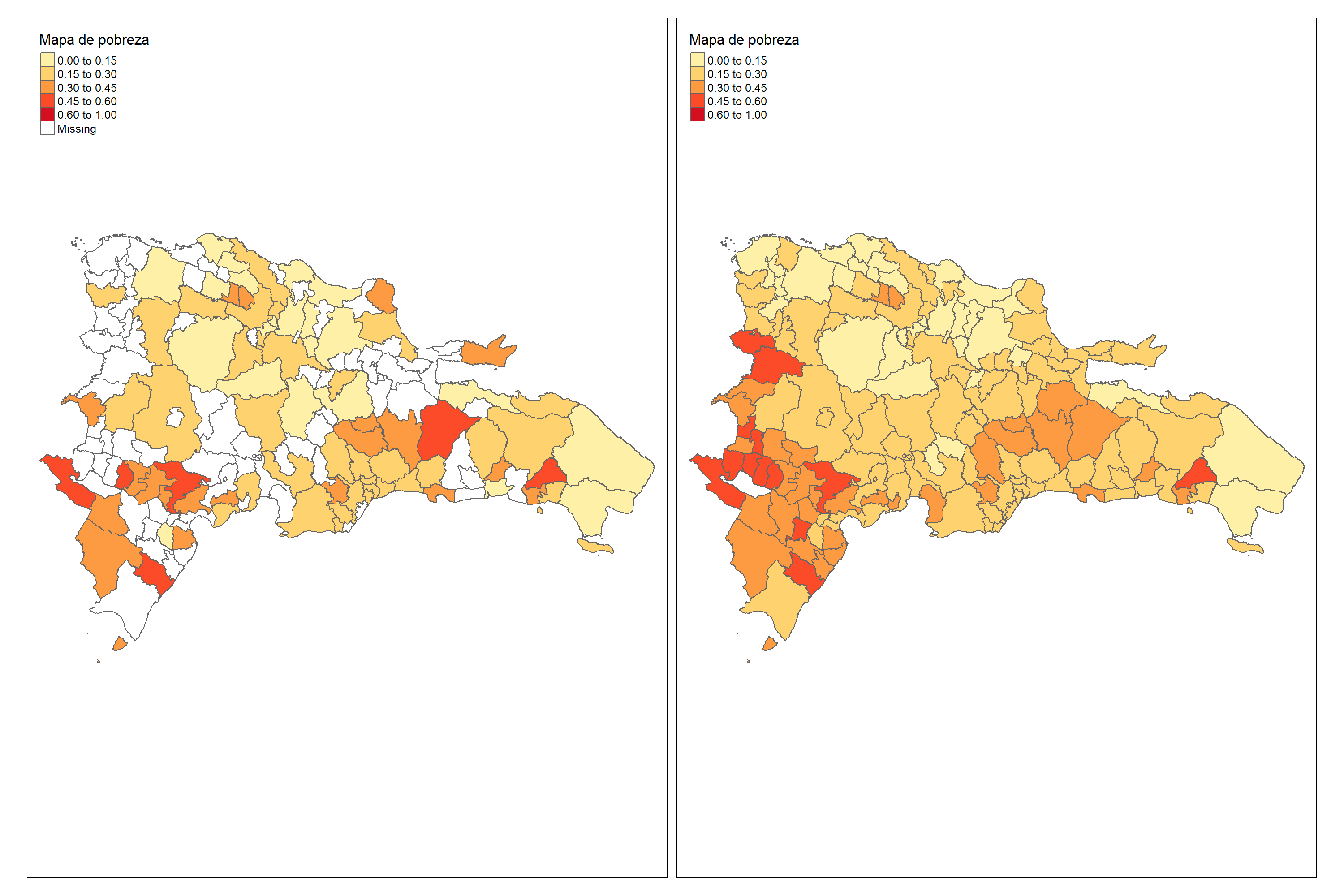
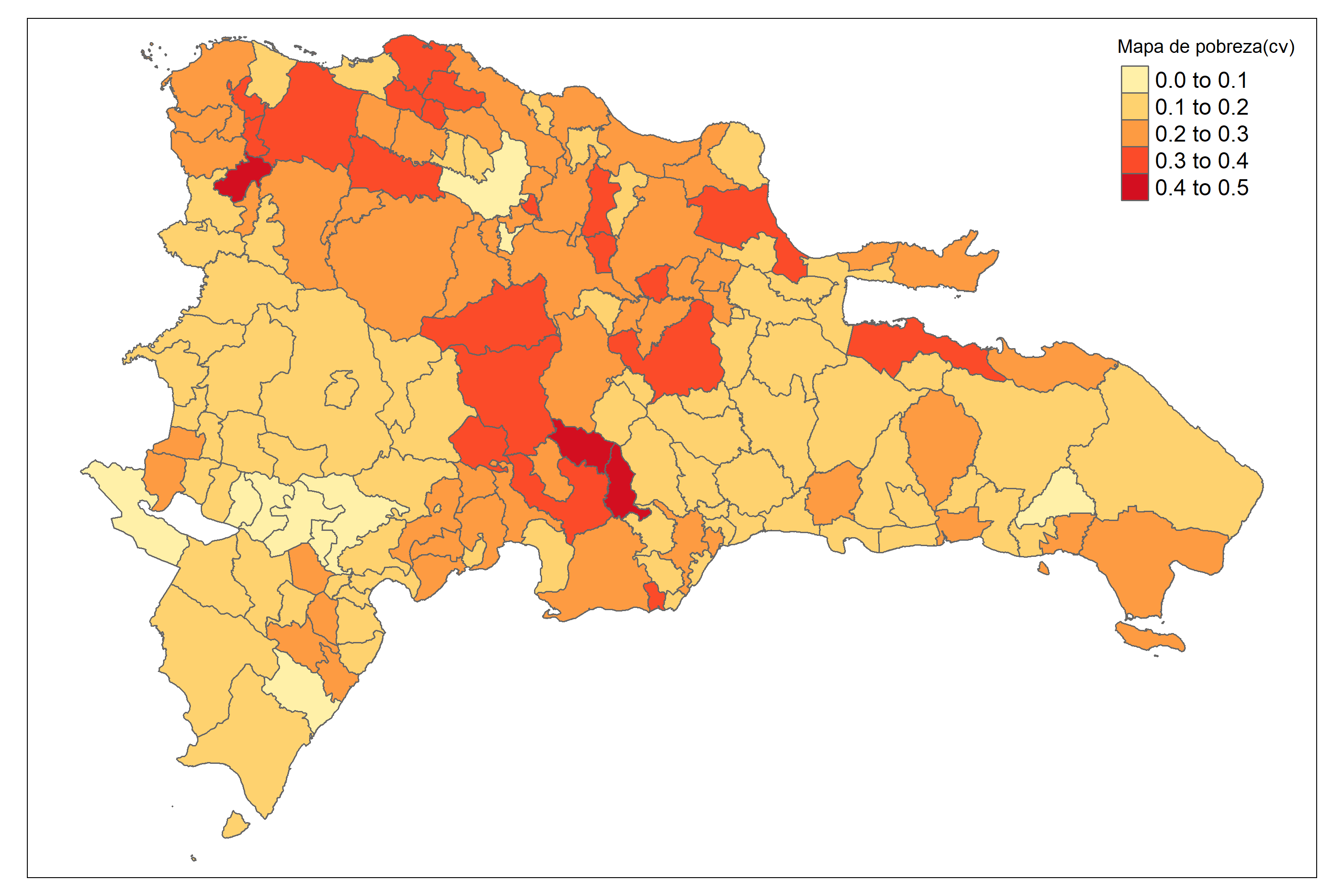
9.2.2.3 Mapa del coeficiente de variación.
Ahora, se crea un segundo mapa temático (tmap) llamado Mapa_cv. Utiliza la misma estructura del primer mapa (mapa) creado anteriormente y agrega una capa utilizando la función tm_polygons(). El mapa representa la variable Cv_pred, utilizando una paleta de colores llamada “YlOrRd” y establece el título del mapa con el parámetro title. La función tm_layout() establece algunos parámetros de diseño del mapa, como la relación de aspecto (asp). Finalmente, el mapa Mapa_cv se muestra en la consola de R.
Mapa_cv <-
mapa + tm_polygons(
c("Cv_pred"),
title = "Mapa de pobreza(cv)",
palette = "YlOrRd",
colorNA = "white"
) +
tm_layout(
legend.only = FALSE,
legend.height = 0.95,
legend.width = 0.95,
asp = 0,
legend.text.size = 1,
legend.title.size = 1
)
tmap_save(
Mapa_cv,
"Recursos/Día3/Sesion2/0Recursos/Binomial3_cv.PNG",
width = 3000,
height = 2000,
asp = 0
)
Mapa_cv