14.2 Ejemplo de imputación en una encuesta de ingresos y gastos
Una vez que se ha discutido acerca de los propósitos de la imputación en una encuesta de hogares, se debe escoger un método (o métodos) de imputación y una vez establecido el mecanismo de imputación, generar el conjunto de datos rectangular y completo. En esta sección analizaremos, a la luz de las particularidades de una encuesta de hogares de ingresos y gastos, los pasos que se deben surtir para completar un proceso de imputación. Por sus características, este tipo de encuestas presenta tasas elevadas de ausencia de respuesta de registro, aunque también de individuo.
En general, el levantamiento común de este tipo de encuestas se centra en un trabajo de campo masivo que visita al hogar en varias ocasiones, pidiéndole al respondiente que diligencie sendos cuestionarios, y registre toda la información asociada al gasto y a los ingresos del hogar, durante un periodo de al menos dos semanas. Por supuesto, para que esto pueda realizarse, es necesario contar con la colaboración activa de todos los miembros del hogar. En el mejor de los casos, el encuestador habrá visitado varias veces el domicilio del hogar en el periodo de observación y tendrá un formulario totalmente diligenciado. Sin embargo, en muchas otras ocasiones, a pesar del seguimiento exhaustivo del encuestado, no se obtendrá el gasto de la totalidad de las categorías de la encuesta, sino que se obtendrá información parcial que se transformará en celdas vacías por la ausencia de respuesta. En el peor de los casos se obtendrán cuestionarios diligenciados en porcentaje tan bajo, que al final serán declarados como faltantes, lo cual se transforma en ausencia de respuesta de ese hogar.
El siguiente ejemplo trata de ilustrar de manera escueta cómo se debería realizar el procedimiento de imputación en una encuesta de ingresos y gastos. El lector encontrará varios pasos en esta metodología, puesto que antes de imputar las variables de interés, es necesario conocer qué covariables se relacionan fuertemente con las variables que se quieren imputar. Además de eso, es necesario primero imputar todas las covariables en primer lugar y reemplazar sus valores faltantes con información plausible que pueda ser utilizada en los modelos que se ajusten. Suponga que, para el conjunto de hogares que se consideró con fines de imputación, se observaron al menos las siguientes variables:
- Tamaño del hogar.
- Número de hombres y mujeres dentro del hogar.
- Número de niños y adultos en el hogar.
- Edad del jefe de hogar.
- Estado de ocupación del jefe de hogar.
- Grado educativo más alto del jefe de hogar.
- Número de personas empleadas en el hogar.
El camino que se seguirá en este ejemplo será primero la imputación de los ingresos, como principal covariable del gasto y del consumo. Una vez que se imputaron las covariables, el segundo paso de este proceso se relaciona con la imputación de los filtros, que son las preguntas que se realizan para conocer si un hogar ha adquirido un bien o servicio específico. El resultado de este paso produjo el tercer paso dedicado a la imputación de los valores de gasto anualizados en cada unidad. Esta serie de pasos metodológicos ha sido recomendados por diferentes agencias de estadística, incluyendo institutos y oficinas nacionales de estadística. Por ejemplo, Hayes y Watson (2009) y Sun (2010) siguen esta metodología en el Australian Bureau of Statistics para imputación en la encuesta Household, Income and Labour Dynamics in Australia (HILDA)
14.2.1 Imputación del ingreso
En primer lugar, recuérdese que existen múltiples fuentes de ingreso en el hogar, como por ejemplo el ingreso el trabajo, la propiedad de activos, la producción de servicios para consumo propio, y las transferencias (condicionadas o no) gubernamentales. Además debe ser notado que tanto teórica como empíricamente, los ingresos han demostrado ser un potente predictor de los gastos (Starick y Watson 2011).
La imputación del ingreso podría estar basada en un enfoque de modelos predictivos y la técnica que se podría utilizar para imputar esta covariable es la del vecino más cercano con regresión. De esta forma, se define un modelo lineal para las unidades encuestadas y luego se estiman los coeficientes de regresión para obtener un valor pronosticado que se computa para las unidades que faltan. Así, para cada unidad con información faltante en el ingreso, se identifica un solo donante que corresponderá al hogar cuyo ingreso disponible es más cercano a la predicción del modelo de regresión. Por ende, todos los componentes de los ingresos serán imputados con la información del donante. El modelo lineal se describe como se indica a continuación y la predicción de los ingresos para los hogares faltantes se calcula utilizando una regresión lineal.
\[\tilde{y}_k = \mathbf{x}_k \hat{\boldsymbol{\beta}}_i\]
Donde, \(\tilde{y}_k\) es el valor pronosticado del ingreso disponible para el hogar \(k\), \(\mathbf{x}_k\) es el vector de las covariables del modelo, y los coeficientes de regresión estimados están dados por:
\[ \hat{\boldsymbol{\beta}}_i = \left(\sum_{r_i} a_k\mathbf{x}_k\mathbf{x}_k'\right)^{-1} \sum_{r_i} a_k\mathbf{x}_ky_k \]
Este vector de coeficiente de regresión \(\hat{\boldsymbol{\beta}}_i\) se produce a partir de un ajuste de regresión múltiple utilizando los datos \((y_k, \mathbf{x}_k)\) disponibles para cada unidad \(k \in r_i\) con pesos \(a_k\) especificados adecuadamente para incluir la posible heteroscedasticidad de los residuales. Por ejemplo, es recomendable que la información incluida en el vector de covariables \(\mathbf{x}_k\)) contenga la siguiente información:
- Composición del hogar: número de adultos, número de niños, número de hombres, número de mujeres, edad adulta media, edad media de los niños, edad de la persona más joven, edad de la persona mayor, edad del jefe de hogar, grado educativo más alto del jefe de hogar.
- Ocupación y fuerza de trabajo: situación laboral del jefe de hogar, número de personas empleadas, número de desempleados en el hogar.
- Calidad de la vivienda: creada creado a partir de la sección de calidad de la vivienda, incluye por ejemplo, un índice de hacinamiento (como la relación entre número de habitaciones utilizadas principalmente para dormir y el número de personas en el hogar), el material de las paredes, y la principal fuente de agua potable en el hogar.
- Ubicación del hogar: municipalidad y provincia, como primera y segunda desagregación cartográfica del país.
Asumiendo que valores similares de las predicciones del modelo lineal \(\tilde y\) producirán valores similares en las observaciones del ingreso \(y\), podríamos pedir prestado un valor real de ingreso \(y\) para imputar el valor faltante con la información de este vecino que tiene valores similares en las predicciones \(\tilde y\) del modelo lineal. Así, el valor imputado para la unidad \(k\) es dada por
\[\hat{y}_k = y_{l(k)}\]
Donde \(l(k)\) es el elemento donante, determinado por medio de la minimización de una medida simple de distancia entre todos posibles donantes \(l\) y la unidad \(k\). Esta distancia está dada por:
\[ D_{lk} = |\tilde y_k - y_l| \]
El donante \(l\) al elemento \(k\) será aquel hogar en el conjunto \(r_i\) con la menor distancia \(D_{lk}\). Como regla general, todo los donantes deben estar ubicados en la misma provincia que la unidad faltante. La figura 14.1 muestra un diagrama de caja junto con el histograma de los ingresos (antes de la imputación), así como la relación lineal entre los valores pronosticados derivados del modelo y los valores imputados tomados de los donantes.
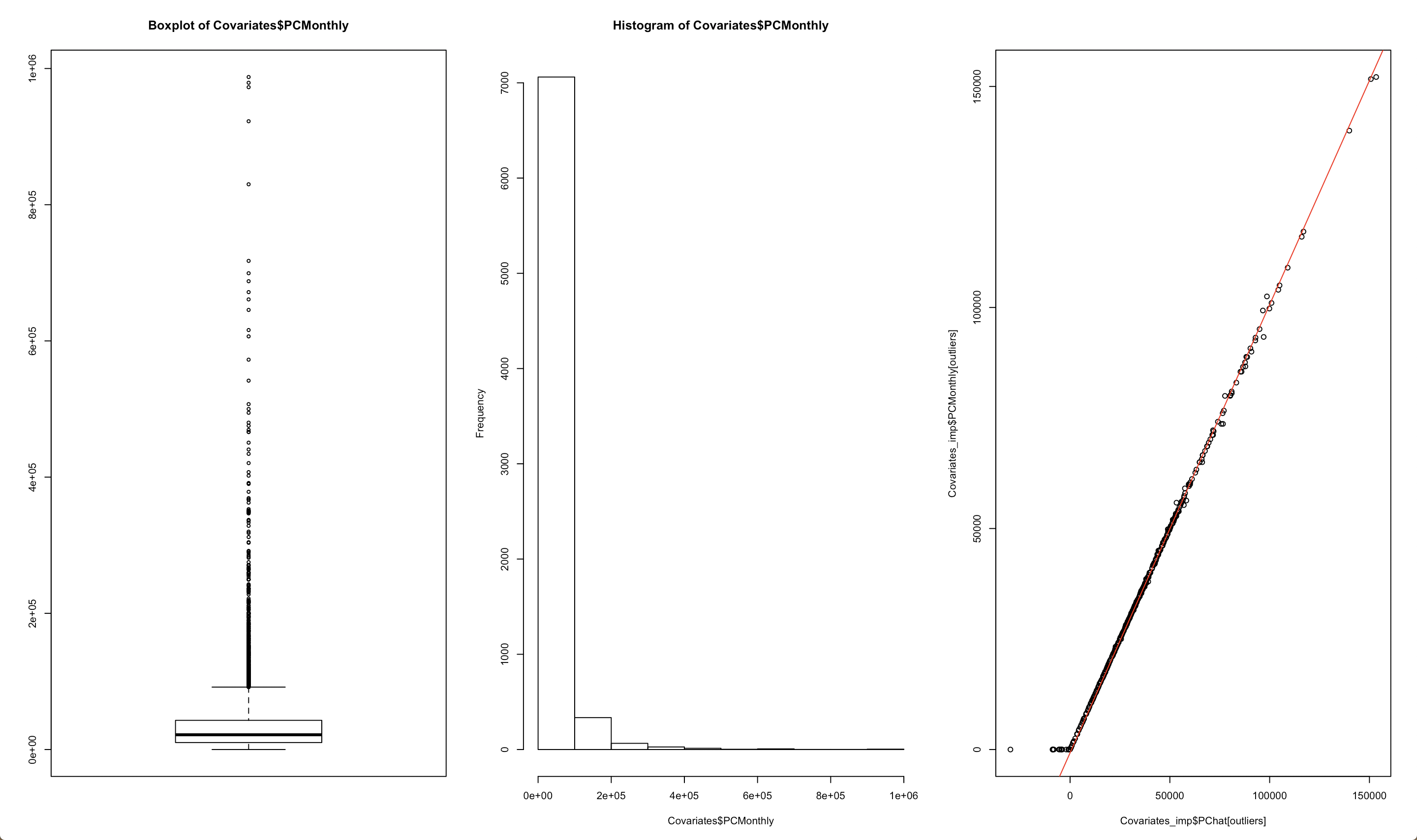
Figura 14.1: Distribución de los ingresos (izquierda y centro) y Relación entre los valores predichos e imputados para los hogares con datos de ingresos faltantes (derecha).
Por último, nótese que si la base de datos contiene hogares que reportaron un ingreso nulo en todo el año, es posible que esos valores se consideren como faltantes porque se asume que la probabilidad de que un hogar no genere ningún tipo de ingreso durante todo un año es bastante baja. Además, los hogares con ingresos superiores a un límite también pueden ser considerados como valores atípicos y luego ser imputados.
14.2.2 Imputación del filtro
El siguiente paso, luego de haber logrado imputar con éxito las covariables determinantes del gasto, es precisamente utilizarlas para lograr imputar el gasto en bienes o servicios. Por lo general, las encuestas de ingresos y gastos preguntan si el hogar consumió o adquirió cierto bien o servicio específico. En caso de responder afirmativamente, se pregunta por la cantidad de dinero gastado en el bien o servicio y por la cantidad de artículos adquiridos en el periodo de referencia; en caso de responder negativamente, se procede a preguntar por el siguiente bien o servicio. Por supuesto, diferentes artículos tiene diferentes tasas de respuesta en sus filtros. De aquí en adelante, el valor a ser imputado en esta etapa es dicotómico: sí o no. Si el valor imputado hubiera sido no, eso significaría que el hogar no debería tener ningún gasto asociado a ese registro. Debido a la naturaleza del filtro, un modelo de regresión logística es conveniente para modelar la ausencia de respuesta en el filtro. De esta manera, la probabilidad de consumo (o compra) a un artículo \(i\) en particular es \(p_k = Pr(Filtro_i = 1)\) y puede ser estimada por medio del siguiente modelo de regresión logística:
\[ \tilde{p}_k = logit^{-1}(\mathbf{x}_k \hat{\boldsymbol{\beta}}_i) = \frac{exp(\mathbf{x}_k \hat{\boldsymbol{\beta}}_i)}{1+exp(\mathbf{x}_k \hat{\boldsymbol{\beta}}_i)} \]
Las covariables incluidas en la matriz \(\mathbf{x}\) podrían ser las mismas utilizados para la imputación de los ingresos y, por supuesto, los ingresos en sí. Es decir, las covariables incluidas serían la composición del hogar, el estado ocupación y fuerza de trabajo de los miembros del hogar, la calidad de la vivienda, la ubicación del hogar y los ingresos del hogar. Asumiendo que los similares valores de \(\tilde p\) producirán valores de filtro similares, podemos “pedir prestado” un valor de filtro para imputar el que falta de un vecino con un valor similar de \(\tilde p\). Por lo tanto, el valor imputado del filtro para la unidad \(k\) es dado por \(Filtro_k = Filtro_{l(k)}\); donde \(l(k)\) es el elemento donante, determinado por la minimización de la distancia \(D_{lk} = |\tilde p_k - p_l|\). Se enfatiza en que el donante \(l\) del elemento \(k\) es el elemento en el conjunto \(r_i\) con el valor más pequeño de la distancia \(D_{lk}\).
Por regla general, todo los donantes deben estar en la misma provincia que la unidad con el valor faltante. Por ejemplo, considere el artículo arroz, para el cual algunos hogares no proveyeron ninguna respuesta asociada al filtro de compra. Como este es un artículo de consumo masivo en nuestra región, se supondría que la mayoría de hogares respondiera que efectivamente ha comprado arroz en el periodo de referencia. De esta manera, al utilizar la regresión logística como modelo para la ausencia de respuesta del filtro del arroz, es posible encontrar que la distribución de las probabilidades estimadas de compra de arroz esté sesgada hacia el valor uno y alejada del valor cero, como lo muestra la figura 14.2. Está claro que la distribución de los valores imputados también debería estar cargada hacia el uno, reflejando la realidad de la compra de un artículo esencial como el arroz.
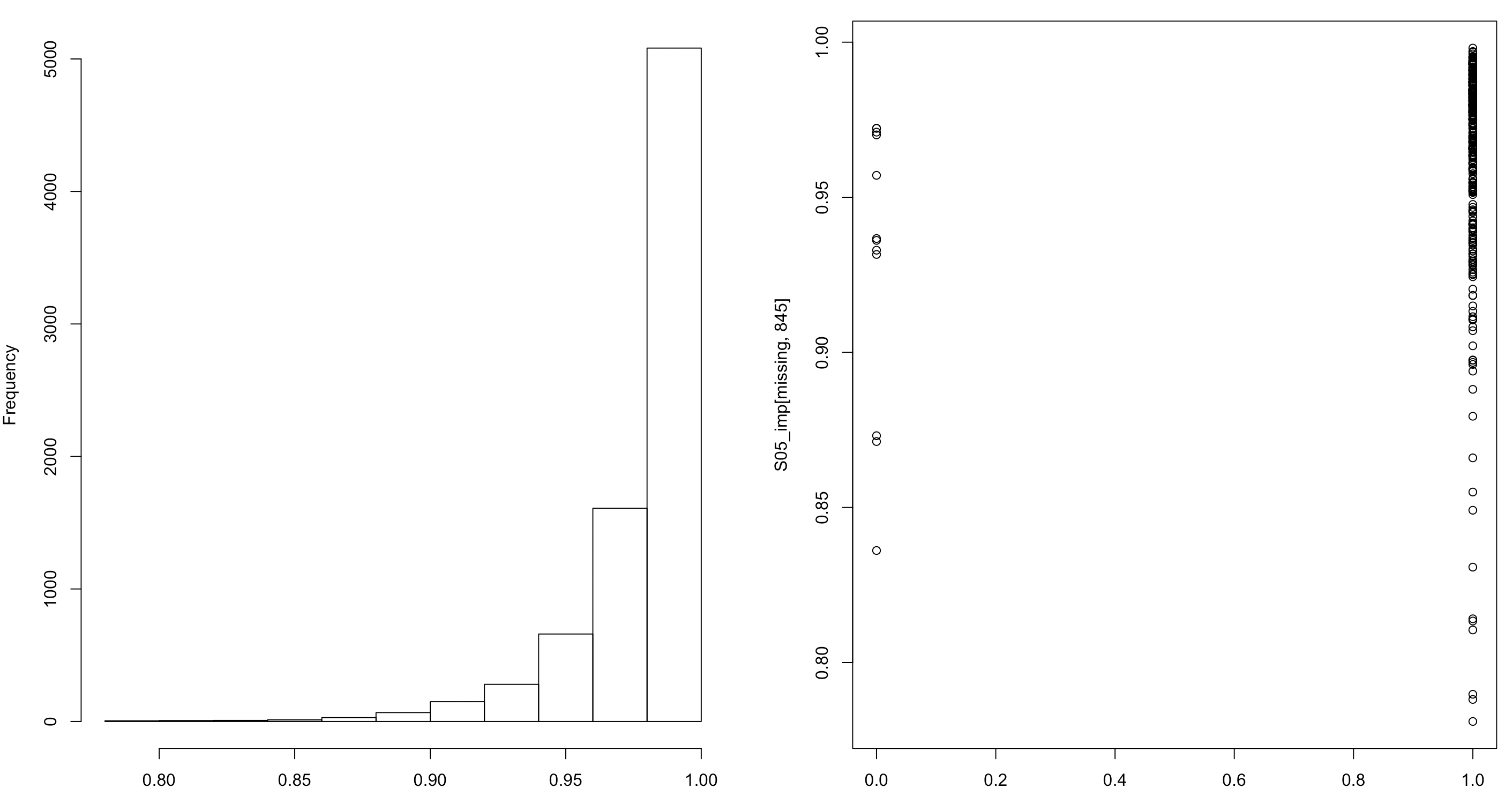
Figura 14.2: Distribución de las probabilidades estimadas de compra de arroz (izquierda) y valores imputados para los hogares con valores faltantes en el filtro (derecha).
Por otro lado, el filtro para algunos artículos de bajo consumo estará más sesgado hacia el valor cero. La figura 14.3 muestra la distribución de las probabilidades estimadas de compra de un artículo de bajo consumo, así como los valores imputados.
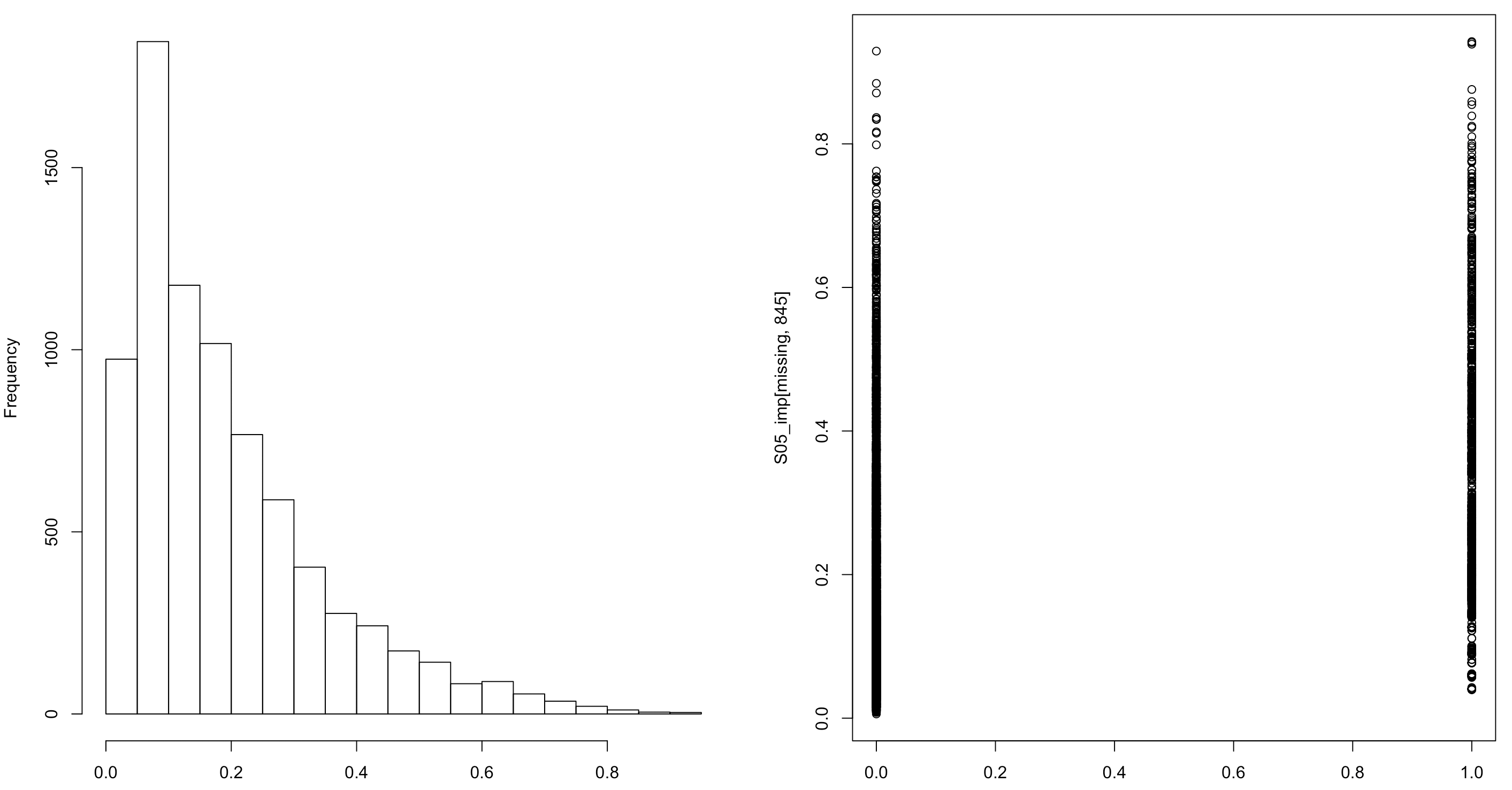
Figura 14.3: Distribución de la probabilidad estimada de compra de un artículo de bajo consumo (izquierda) y sus valores imputados para los hogares que no respondieron el filtro (derecha).
14.2.3 Imputación del gasto
Éste es el paso final del proceso de imputación y está fuertemente influenciado por los resultados de la imputación de la pregunta de filtro. En este paso, los hogares cuyo valor imputado de filtro es cero automáticamente tendrá un cero imputado como la cantidad de dinero gastado en ese artículo. Es decir, si el resultado de la imputación en el filtro es cero, esto implica directamente que el hogar no compró (o produjo) el artículo en el periodo de referencia, y por tanto la frecuencia de compra, la cantidad que registros comprados y la cantidad de dinero gastado en ese artículo debe ser cero. Las unidades restantes deben tener un valor observado o imputado de uno en el filtro, y por lo tanto los valores faltantes del gasto deben ser imputados.
Observe que el grupo de donantes está restringido a los que tienen un valor de gasto distinto de cero en el artículo específico. Es decir, para aquellas unidades con un valor de filtro distinto de cero, un donante debe ser identificado. Para la imputación del gasto, la técnica del vecino más cercano con el método de regresión puede considerarse en el mismo sentido que fue implementado en la imputación de los ingresos. Por lo tanto, se considera un modelo lineal en donde las covariables incluidas en la matriz \(\mathbf{x}\) son la composición del hogar, el estado de ocupación y fuerza de trabajo, la calidad de la vivienda, la ubicación del hogar y los ingresos.
Volviendo a los ejemplos anteriores, la figura 14.4 muestra la distribución de los gastos imputados en consumo de salmón. Se nota que la cantidad de dinero gastado en este artículo es baja y que la relación entre los valores pronosticados del modelo y los valores imputados es fuertemente lineal.
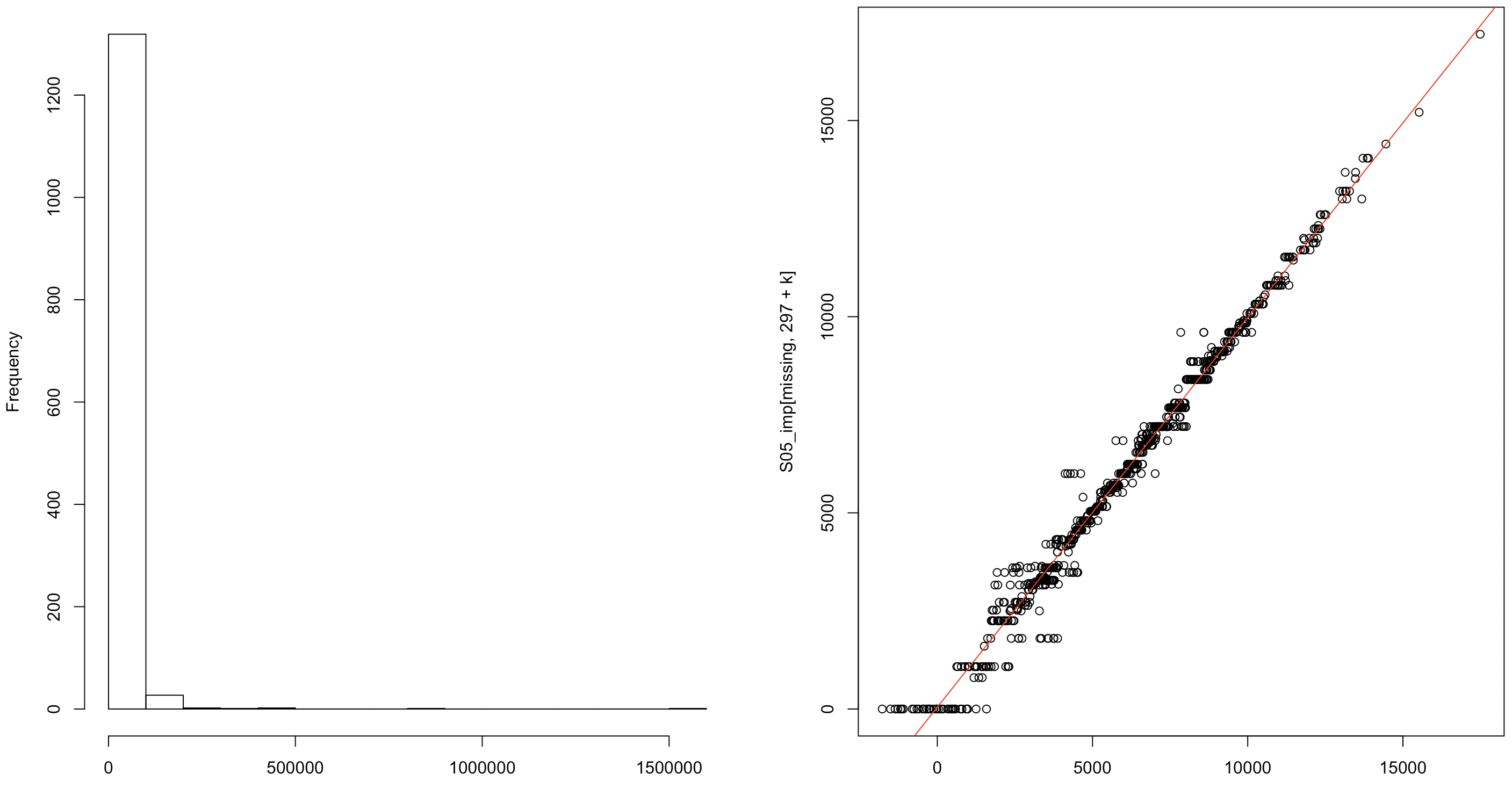
Figura 14.4: Distribución de los gastos imputados sobre el salmón (izquierda) y relación entre los valores predichos e imputados para los hogares con valores faltantes en el gasto (derecha).