12.5 Posibles soluciones
Al lidiar con la ausencia de respuesta, podemos distinguir algunas prácticas que guían a diferentes tratamientos metodológicos diferentes. En general, se pueden distinguir las siguientes prácticas:
- Imputación total: se trata de imputar todos los valores faltantes para los individuos con al menos un valor perdido. En otras palabras, la imputación se considera como la única forma de tratar la ausencia de respuesta.
- Ponderación total: se trata de ponderar cada una de las variables de interés, así sea de manera diferenciada. No se utiliza la imputación y existirán tantos conjuntos de factores de expansión como variables con valores perdidos.
- Eliminación total: se trata de eliminar todos los registros con algún valor perdido y hacer el análisis con el conjunto restante de valores respondidos.
- Enfoque combinado: se trata de imputar únicamente en los elementos que tienen al menos un registro (no todos) perdido y modificar los factores de expansión en aquellos casos en donde hay omisión de todos los registros del cuestionario.
Siguiendo la notación de C.-E. Särndal y Lundström (2006), consideramos una muestra de unidades \(s\), de la cual \(r\) denota el conjunto de respondientes que han contestado a una o más de las \(I\) variables de interés. Por tanto, una unidad que no responde a ninguna variable pertenece al conjunto \(s-r\). El conjunto de unidades que han respondido a una variable del estudio en particular se denota por \(r_i\). Nótese que
\[ r_i\subseteq r \subseteq s \]
Finalmente, si se supone que \(y_k\) es faltante y se considera para la imputación, entonces \(\hat{y}_k\) denotará su valor imputado. La figura 12.4 ilustra15 cómo, después de la recolección de datos, hay individuos que no respondieron a una o todas las variables de la encuesta. En esta ilustración, las unidades están representadas por las filas y las variables por las columnas. Observe que lo primeros tres individuos contestaron a todas las preguntas del cuestionario; el cuarto individuo no contestó las últimas dos preguntas; el quinto individuo no contestó ni la primera ni la última pregunta; el sexto individuo no contestó a la tercera pregunta; y así sucesivamente, hasta llegar a los últimos dos individuos quienes no contestaron a ninguna pregunta del cuestionario. Para este ejemplo particular, se observa que:
- El número de variables de interés en la encuesta de hogares es \(I=8\).
- El número de unidades incluidas en la muestra \(s\) es \(n=\#(s)=14\).
- El número de respondientes efectivos en la primera variable es \(\#(r_1)=10\), en la segunda variable es \(\#(r_2)=9\), y así sucesivamente hasta notar que el número de respondientes efectivos en la última variable de la base de datos es de \(\#(r_8)=8\).
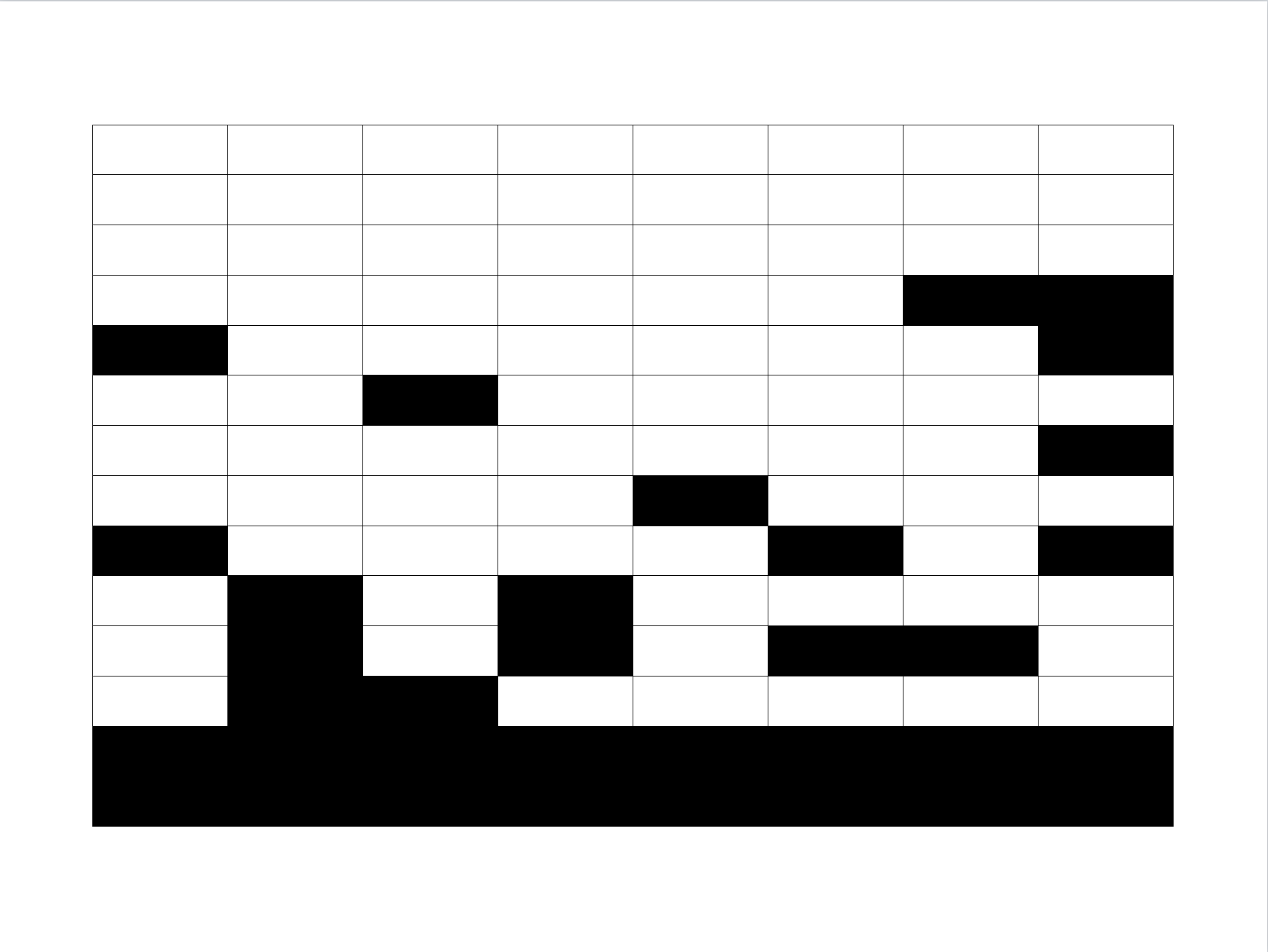
Figura 12.4: Un conjunto de datos después del proceso de observación.
12.5.1 Imputación total
En este enfoque se imputarían todos los valores \(y_k\) que están perdidos, sin importar si la pérdida es debida a la ausencia del registro o del individuo. En este caso, tendríamos un conjunto completo de datos con los valores \(\{y_{\circ \ k}: k\in s\}\), donde
\[ y_{\circ \ k} = \begin{cases} y_k, \ \text{for $k \in r_i$} \\ \hat{y}_k, \ \text{for $k \in s - r_i$} \end{cases} \]
y \(\hat{y}_k\) es el valor imputado. Por ejemplo, el estimador del total utilizando este enfoque estaría dado por la siguiente expresión.
\[ \hat{t}_{y,\pi} = \sum_s d_{k}y_{\circ \ k} = \sum_{r_i}d_{k}y_k + \sum_{s - r_i}d_{k}\hat{y}_k \]
La figura 12.5 muestra un ejemplo de las unidades que serían consideradas para el análisis después de la imputación. Nótese entonces que las tres unidades que respondieron todas las preguntas del cuestionario entran al análisis sin ningún ajuste; mientras que las nueve unidades que no respondieron a todo el cuestionario entran al análisis habiéndose imputado las celdas correspondientes a la ausencia de respuesta; además, las dos unidades que no respondieron ninguna pregunta del cuestionario también entran al análisis puesto que todas sus respuestas fueron imputadas. Luego, en este enfoque todas las unidades en el conjunto \(s\) se consideran para el análisis posterior.
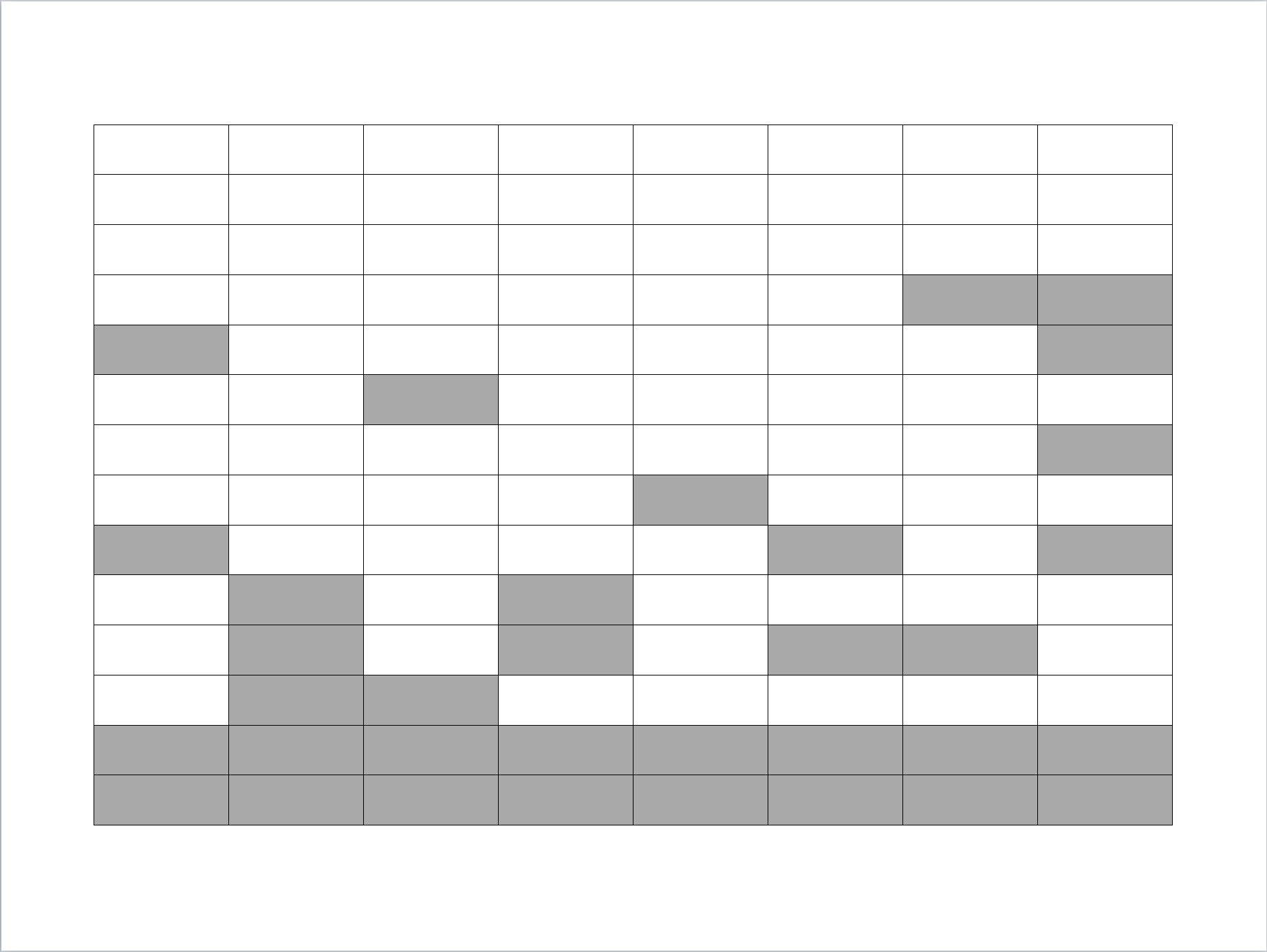
Figura 12.5: Imputación total: todas las unidades que no respondieron son imputadas (las celdas en gris indican los valores que fueron imputados).
12.5.2 Ponderación total
Al usar el enfoque de ponderación total es posible usar pesos de calibración específicos \(w_k = d_k F_{ik}\) que compensarían la ausencia de respuesta de unidad y de registro. De esta forma, el estimador del total estaría dado por la siguiente expresión:
\[ \hat{t}_{y,cal} =\sum_{r_i}w_ky_k = \sum_{r_i}d_k F_{ik} y_k \]
Si todos los \(r_i\) son diferentes, entonces cada variable de estudio requerirá un conjunto de ponderadores diferentes. Al final este enfoque induce un número no uniforme de casos por variable. Para este esquema, se utilizan pesos \(w_k^{(i)}\) para cada variable \(i \in I\) que compensan la ausencia de respuesta de la unidad. Si todos los \(r_i\) son diferentes, cada variable de estudio requerirá un conjunto de pesos diferente.
Siguiendo con el ejemplo, a partir de la figura 12.6 se nota que la primera variable del cuestionario fue respondida por 10 personas, y cuatro personas no respondieron esta pregunta. Por lo tanto, en este enfoque se crearán pesos \(w_k^{(1)}\) para cada \(k\in r_1\) que ponderen satisfactoriamente la información recolectada en esta variable. Sin embargo, este conjunto de pesos no será único, puesto que, en particular, la segunda variable del cuestionario fue respondida por nueve personas, y tres personas no respondieron esta pregunta. Por lo tanto, en este enfoque se crearán pesos \(w_k^{(2)}\) para cada \(k\in r_2\) que ponderen esta información recolectada en esta variable. Nótese que en general \(w_k^{(1)} \neq w_k^{(2)}\) y, por ende, cada una de las \(I=8\) variables del estudio tendrá su propio conjunto de ponderadores.
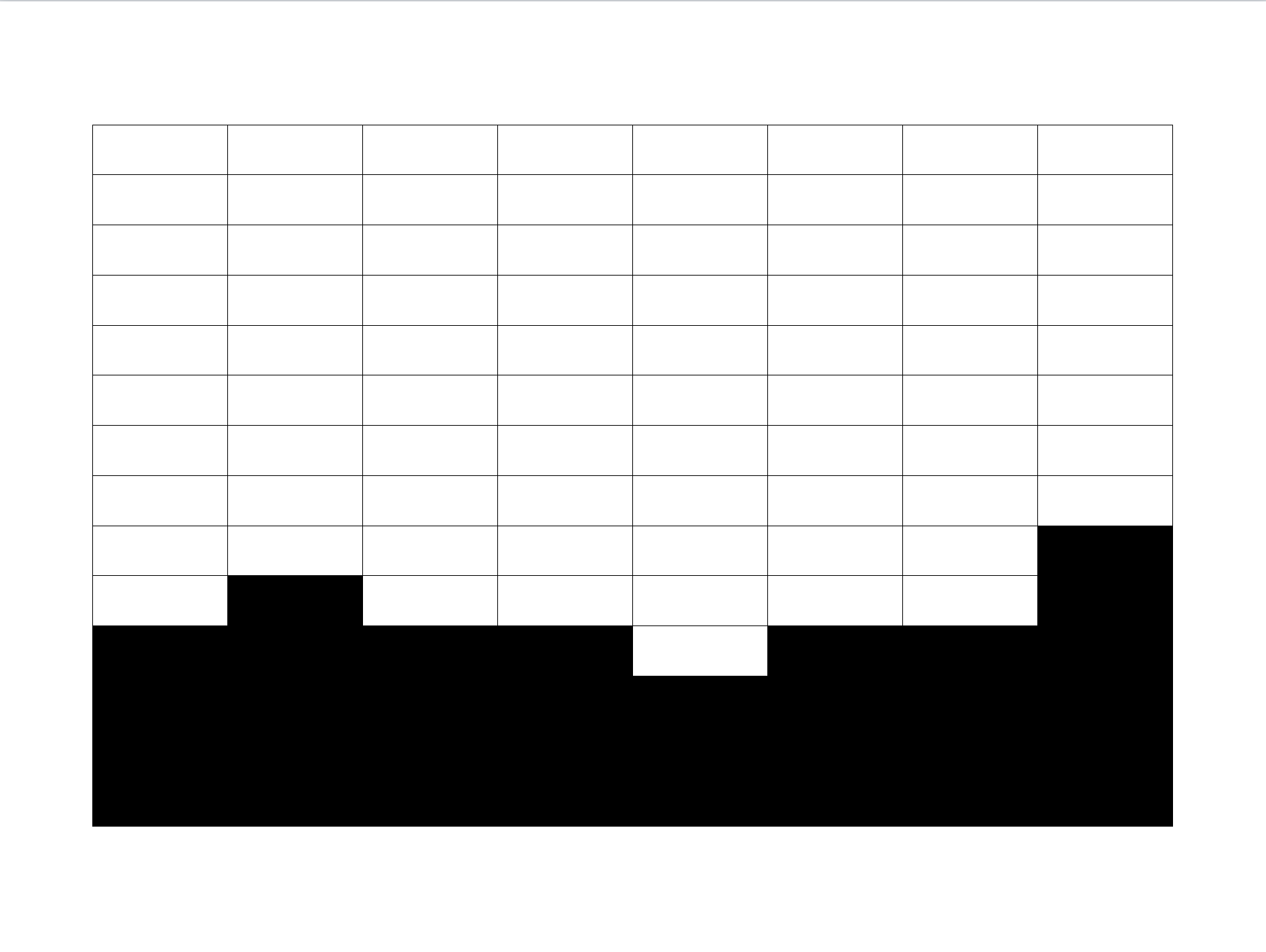
Figura 12.6: Ponderación total: cada variable tendrá un conjunto de pesos diferente. No se utiliza ningún método de imputación.
12.5.3 Eliminación total
En este enfoque se eliminarán de la base de datos todas las unidades que contengan al menos un registro perdido. Se recomienda fuertemente abstenerse de tomar este camino, puesto que, aunque induciría un solo conjunto de ponderadores, tendríamos un decrecimiento considerable y deliberado en el tamaño de muestra, asociado con pérdida de información, incremento sustancial de sesgos y decremento de la precisión de los estimadores. Note que en este enfoque sólo las unidades del conjunto de respondientes efectivos en todas las variables se consideran para el análisis posterior de la encuesta. Este subgrupo de individuos está dado por: \[ \bigcap_{i=1}^I r_i \] Por supuesto, en general, esto no es aconsejable puesto que trae problemas de sesgo, dado que las unidades que contestaron todo el cuestionario generalmente difieren de forma estructural de las unidades que no contestaron; además trae problemas de eficiencia estadística, puesto que el tamaño de la muestra efectiva, después de la eliminación de unidades, será insuficiente para garantizar los mínimos requeridos en la inferencia.
La gráfica 12.7 representa este enfoque en donde es evidente que el decrecimiento en el tamaño de muestra podría tener repercusiones nefastas en la inferencia de la encuesta. Teniendo en cuenta el ejemplo anterior, solo tres unidades serían tenidas en cuenta para el análisis de la información, mientras que nueve unidades, que no contestaron al menos una pregunta, más las dos unidades que no contestaron ninguna pregunta, serían eliminadas del análisis estadístico. Es decir, la mayoría de unidades de la muestra inicial serían descartadas.

Figura 12.7: Enfoque de eliminación: únicamente se consideran las unidades que respondedieron a todas las varaibles.
12.5.4 Enfoque combinado
Por el contrario, es recomendable escoger un camino parsimonioso que combine estas estrategias de forma diferencial a lo largo de la encuesta. El enfoque combinado usa la imputación para afrontar la ausencia de respuesta por registro para las variables (columnas de la base de datos) específicas que lo necesiten y luego utiliza un ajuste a los factores de ponderación para afrontar la ausencia de respuesta por unidad (filas de la base de datos). Usualmente, los pesos finales se producen utilizando un enfoque de calibración que hace uso de información auxiliar externa.
Cuando se presenta ausencia de respuesta por registro y por unidad, el enfoque combinado imputa primero para luego obtener una matriz rectangular completa. Luego de lo anterior se procede a realizar un ajuste a los ponderadores. El conjunto de datos completo para la variable de interés \(y\) está dado por \(\{y_{\circ \ k}: k\in r\}\)
\[ y_{\circ \ k} = \begin{cases} y_k, \ \text{for $k \in r_i$} \\ \hat{y}_k, \ \text{for $k \in r - r_i$} \end{cases} \]
En donde \(\hat{y}_k\) es el valor imputado. Note que en el enfoque de imputación total, también se imputa para \(k \in s-r\). La gráfica 12.8 representa este enfoque parsimonioso en donde los valores imputados (en gris) entran a ser parte de la inferencia y las unidades que nunca respondieron (en negro) y que tienen todos sus registros faltantes son retiradas de la base de datos final.
Se observa que los dos últimos individuos de la muestra fueron totalmente descartados puesto que no contestaron ninguna pregunta del cuestionario; además, para la primera variable, los valores del quinto y noveno individuo fueron imputados. De la misma manera, para la segunda variable, los valores de los individuos diez, once y doce fueron imputados; y así sucesivamente, hasta llegar a la última variable en donde los valores de los individuos cuatro, cinco, siete y nueve fueron imputados.
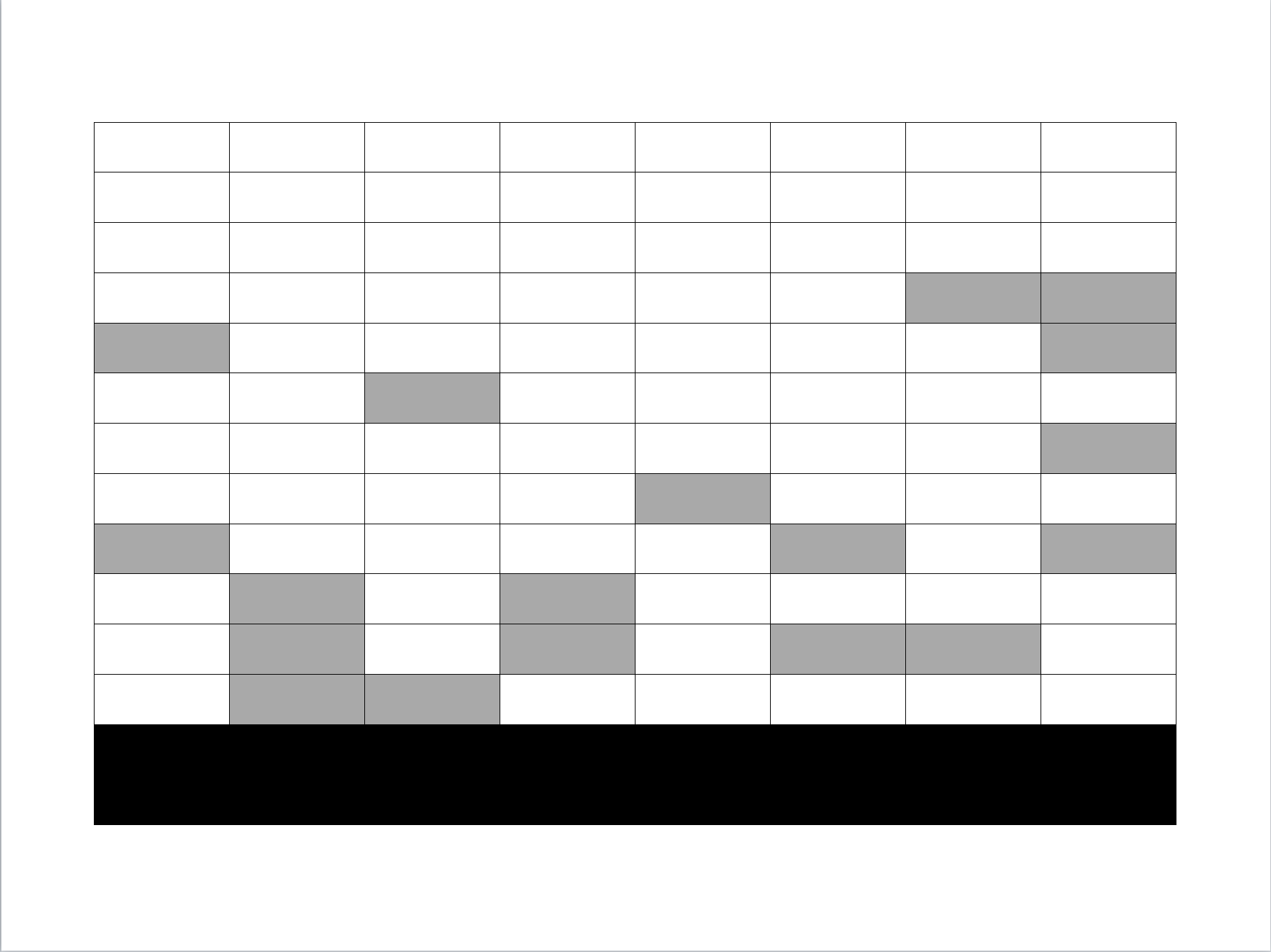
Figura 12.8: Enfoque combinado: las unidades que no respondieron a ningún ítem son eliminadas del análisis y los respondientes parciales son imputados.
Los capítulos anteriores profundizaron en el tema de la creación de factores de expansión para los individuos presentes en la base de datos final. De tal forma que en los capítulos posteriores se abordará algunas metodologías de imputación que pueden ser recomendables a la hora de completar una base de datos estructurada y rectangular cuyas entradas estén completas. Antes de introducir estos temas se presentarán algunas medidas descriptivas que pueden ser usadas para generar alertas sobre la pérdida de representatividad debido a la ausencia de respuesta.
Referencias
Las celdas en color blanco representas registros respondidos y las celdas en color negro representan registros no respondidos y faltantes↩︎