19.3 Secuencia lógica para crear reglas de supresión
En esta sección se ha querido enfatizar el hecho de que la precisión de una estimación recae directamente en los intervalos de confianza, los cuales pueden ser descompuestos en elementos fundamentales que permiten crear una secuencia lógica de revisión, publicación o supresión de cifras. Nótese que lo anterior se basa en que la longitud de los intervalos de confianza induce la seguridad de que un estimador es o no es preciso. Considere los siguientes ejemplos prácticos:
- La incidencia de la pobreza en un departamento de un país se estimó en \(5,2\)%, con un intervalo de confianza de (\(5,15\)%, \(5,25\)%).
- La tasa de desocupación en el país para los hombres se ubicó en \(7,5\)%, con un intervalo de confianza de (\(7,1\)%, \(7,9\)%); mientras que para las mujeres se ubicó en \(9,2\)%, con intervalo de confianza de (\(8,8\)%, \(9,6\)%).
- La tasa de asistencia neta estudiantil en primaria para el último quintil de ingreso se estimó en \(85\)%, con un intervalo de confianza de (\(48,2\)%, \(100,0\)%).
Claramente, en la última situación ejemplificada, el intervalo de confianza no brinda la precisión adecuada para que una Oficina Nacional de Estadística publique esta cifra confiadamente, o para que un gobierno pueda realizar algún tipo de política pública educativa, y mucho menos para estimar los recursos que una de intervención estatal sobre la población de interés. Como se ha descrito a lo largo de este documento, utilizar únicamente el coeficiente de variación como estándar para la supresión de cifras es un criterio que no tiene en cuenta toda las variantes asociadas a la inferencia en un muestreo complejo. A continuación se incorporan algunas recomendaciones internacionales que incorporan otros criterios adicionales a este.
- Coeficiente de variación: CEPAL (2018b) realizó una revisión de las experiencias internacionales, con base en la información publicada en las páginas web de los INE, para determinar cómo son usados los criterios de supresión de información y los umbrales que las oficinas nacionales de estadística definen para la validación de las cifras. Para encuestas de hogares, se encontró que Estados Unidos y los países del Mercosur utilizan un umbral de \(CV > 30\%\), Canadá y México usan como referencia un umbral del \(CV > 25\%\), Chile y Costa Rica utilizan un umbral del \(CV > 20\%\), Ecuador y Perú utilizan un umbral del \(CV > 15\%\), mientras que Colombia usa un umbral del \(CV > 10\%\). De esta forma, cualquier cifra estimada cuyo coeficiente de variación sea mayor al umbral predefinido es suprimida o marcada como una cifra poco confiable.
- Tamaño de muestra: este criterio debe ser considerado como uno de los más importantes a la hora de decidir la ruta de publicación de una cifra, puesto que los desarrollos teóricos en términos de inferencia estadística para encuestas dependen de este término. La cobertura de los intervalos de confianza y la distribución de los estimadores dependen de qué tanto el tamaño de la subpoblación como su tamaño de muestra asociado no sean pequeños. En este espíritu, Barnett-Walker et al. (2003) proponen que todas las estimaciones basadas en un tamaño de muestra menor a 100 unidades deberían ser suprimidas o marcadas como no confiables.
- Tamaño de muestra efectivo: al igual que con el anterior criterio, el tamaño de muestra efectivo induce que las aproximaciones teóricas, en términos de convergencia de las distribuciones de los estimadores y la cobertura de los intervalos de confianza, se cumplan. Hornik et al. (2002) consideran que si el tamaño de muestra efectivo no es mayor a 140, entonces la cifra no debería ser considerada para publicación. Por otro lado, teniendo en cuenta el tamaño de muestra inducido por la transformación logarítmica, Barnett-Walker et al. (2003) afirman que cuando la proporción se encuentra entre \(0.05\) y \(0.95\), entonces el tamaño de muestra efectivo es máximo cuando \(P = 0,5\), siendo su valor \(n_{eff} = 68\).
- Conteo de casos no ponderado: cuando la incidencia de un fenómeno es muy baja y el diseño de la encuesta no lo tuvo en cuenta, entonces es posible que las estimaciones asociadas a tamaños, totales y proporciones sobre este fenómeno no sean confiables. En particular, para las proporciones es posible restringir las estimaciones tales que \(\hat P <0,001\), pero es más expedito crear una regla a partir del conteo de casos en la muestra. Por ejemplo, National Research Council (2015) plantea que si el número de casos no ponderados es menor a 50 unidades entonces la estimación no es publicada.
- Grados de libertad: este criterio apunta a aislar el efecto inflacionario del tamaño de muestra en una encuesta compleja y plantea una aproximación al número de unidades independientes en la inferencia. Además, a medida que crece, la amplitud del intervalo de confianza se estabiliza. Parker, Talih, y Malec (2017) consideran que si los grados de libertad inducidos por la subpoblación son menos de ocho, la cifra debería ser suprimida.
- Coeficiente de variación logarítmico: Esta medida de suavizamiento toma valores altos cuando las proporciones estimadas están demasiado cercanas a cero o a uno. Barnett-Walker et al. (2003) proponen que la cifra debe ser suprimida si el coeficiente de variación logarítmico es mayor que 17.5%.
Nótese que los criterios mencionados en este documento no deberían ser aplicados de manera independiente, sino que tendrían que seguir cierta lógica, puesto que es posible, por ejemplo para una variable con poca homogeneidad en las UPM, que con un tamaño de muestra de \(n=90\), se haya estimado un efecto de diseño de \(DEFF=0,5\), lo cual implicaría un tamaño de muestra efectivo de \(n_{eff}=180\). En este caso, si los criterios de supresión se aplicaran de manera independiente, se concluiría que la cifra debería ser suprimida por tener un tamaño de muestra insuficiente, pero a la vez, que la cifra debería ser publicada, por tener un tamaño de muestra efectivo suficiente. Lo anterior, podría llevar a contradicciones por parte de los INE y malas interpretaciones por parte los usuarios finales de los datos.
De manera general, se recomienda que los INE estudien a profundidad sus políticas de supresión, revisión y publicación de cifras en cada una de las encuestas que realiza y, de manera independiente, defina las reglas apropiadas para cada caso y que los criterios de supresión sean plasmados en forma de diagrama de flujo en la documentación de las encuestas. Además, cada encuesta debería considerar un algoritmo de forma particular; es decir, los criterios de supresión no necesariamente deben coincidir para cada operación estadística, aunque sí debiesen acogerse unos mínimos en cada ONE para garantizar la calidad de la estimaciones publicadas provenientes de las encuestas de hogares.
Teniendo en cuenta las particularidades de la región, en este documento se recomienda mantener un umbral del coeficiente de variación \(CV > 20\%\) y del coeficiente de variación logarítmico \(CV(\hat{L}) > 17.5%\) como generadores de alertas sobre la calidad de la estimación; además se recomienda tener mínimo 14 grados de libertad, los cuales implican al menos 15 UPM que inducirían una convergencia en la distribución del estimador (H. A. Gutiérrez 2016, fig. 8.1). A partir de esta cifra es posible continuar el análisis de las recomendaciones con las particularidades de cada encuesta en cada país. Por ejemplo, # si se espera un mínimo de 15 UPM, y en cada una se seleccionan 12 hogares, entonces la muestra esperada es de 180 hogares, y tomando una tasa de efectividad del 85%, esta se reduce a \(n < 153\) como generados de alertas. Asimismo, tomando en cuenta un efecto de diseño promedio de 2.5 (calculado según el indicador de interés), se obtendría un tamaño de muestra efectivo de \(n_{eff} = 61\) como generador de alertas. Asimismo, se recomienda mantener el conteo de casos no ponderado en \(n_y < 40\) e inmediatamente generar una alerta sobre todas las cifras que reporten un efecto de diseño \(DEFF < 1\).
Por ejemplo, la figura 19.2 muestra una propuesta preliminar, para la estimación de proporciones o razones, en cuanto a los criterios de supresión de cifras. En una primera instancia se realiza la estimación clásica de los parámetros de interés y se genera una tabla que adjunte el cálculo de todos los criterios descritos anteriormente. Luego, dependiendo de la naturaleza del fenómeno investigado, se deben establecer los criterios que se van a tener en cuenta y los umbrales en cada caso. El próximo paso es decidir, para cada cifra de la tabla generada, si se va a publicar o suprimir, y en algunos casos si se revisará la cifra con mayor detenimiento. Por ejemplo, en el diagrama propuesto se definen seis criterios como condiciones necesarias para la publicación inmediata de una cifra; los primeros cuatro, son condiciones necesarias para la revisión temática. Si alguno de los primeros cuatro criterios no se satisface, entonces la cifra es suprimida.
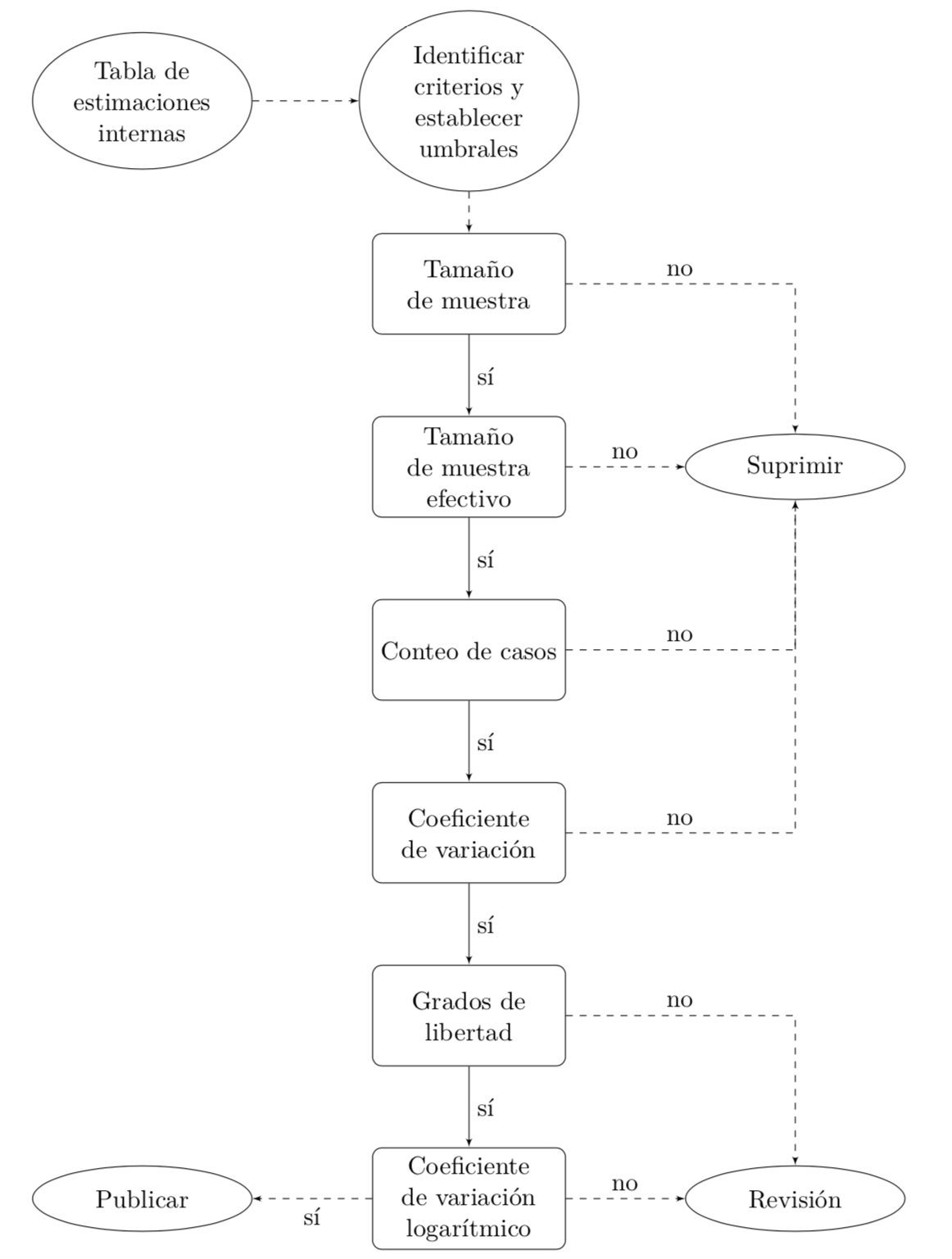
Figura 19.2: Ejemplo de un diagrama de flujo para la publicación, supresión y revisión de estimaciones de proporciones o razones en encuestas de hogares.