9.4 Estimadores de calibración
La calibración se ha establecido como un importante instrumento metodológico en la producción de grandes masas de estadísticas (C.-E. Särndal 2007). Esta metodología integra información auxiliar en las estimaciones de la encuesta, no solo para garantizar la consistencia con las cifras oficiales reportadas por los INE, sino para hacer más eficiente el proceso de estimación. H. A. Gutiérrez (2016) da una breve descripción de este método:
- Suponga que se tiene acceso a un vector de información auxiliar, \(\mathbf{x}_k=(x_{1k}, x_{2k},\ldots,x_{pk})\), de \(p\) variables auxiliares, el cual es conocido para los individuos seleccionados en la muestra.
- Además, por registros administrativos u otras fuentes de confianza, se tiene el conocimiento del total del vector de información auxiliar \(\mathbf{t_X}=\sum_{k\in U}\mathbf{x}_k\).
- El propósito del estudio es estimar el total de la característica de interés incorporando la información auxiliar, dada por \(\mathbf{x}_k (k\in s)\).
- Se requiere que los pesos resultantes cumplan con la siguiente restricción \[ \sum_{k\in s}w_k\mathbf{x}_k = \mathbf{t_X} \] la cual es conocida como la ecuación de calibración.
- El resultado de la calibración es un nuevo conjunto de pesos \(w_k\) que son muy cercanos al inverso de la probabilidad de inclusión del \(k\)-ésimo elemento \(d_k=1/\pi_k\)
En general, en América Latina, la estrategia de estimación utilizada por los INE recurre a la metodología de calibración sobre proyecciones poblacionales en los dominios de representatividad de la encuesta. Por ejemplo, departamento, zona urbana, zona rural, sexo y/o grupos de edad. Algunas ventajas de utilizar estos procedimientos es que las estimaciones tendrán un sesgo despreciable, y los errores estándares serán más pequeños al compararlos con los del estimador de Horvitz-Thompson; de esta forma se crea un sistema de ponderación que reproduce la información auxiliar disponible y que es eficiente al momento de estimar cualquier característica de interés en la encuesta. Esta coherencia entre las cifras oficiales y las que la encuesta puede producir hace que sea preferible el uso de los estimadores de calibración.
En un encuesta de hogares las restricciones de calibración pueden establecerse sobre características de hogares y características de personas al mismo tiempo. De esta forma, por ejemplo, es posible calibrar sobre las proyecciones demográficas de personas y al mismo tiempo controlar las estimaciones del número de hogares en el país de manera conjunta. Estevao y Särndal (2006) discuten una amplia variedad de casos en donde se calibra conjuntamente en distintos niveles de desagregación sobre diferentes esquema de muestreo. Por ejemplo, para la Encuesta Continua de Empleo de Bolivia la calibración está inducida por una post-estratificación sobre los tamaños poblacionales de los cruces resultantes entre las variable Departamento (hay 9 departamentos), Zona (rural y urbano) y PET (con dos categorías: mayor o igual a 10 años y menor de 10 años).
En resumen, utilizar este tipo de estimadores garantiza una consistencia estética, puesto que es deseable que las estimaciones puntuales de las encuestas coincidan con los conteos censales, proyecciones poblacionales, registros estadísticos o registros administrativos. Además, existirá un aumento de la precisión, porque en la búsqueda de la mejor estrategia de muestreo, el estadístico quiere obtener cifras precisas y confiables que induzcan intervalos de variación angostos y menores errores de muestreo. Por último, si existe una integración adecuada de la información auxiliar, se disminuye el sesgo generado por la ausencia de respuesta (debido a los individuos) o por la falta de cobertura (debido a los defectos del marco de muestreo).
9.4.1 Ganancia en eficiencia
Para mostrar cómo los estimadores de calibración inducen menores varianzas que los estimadores comunes, se planeó el siguiente experimento de simulación empírica:
- Se generaron cuatro conjuntos de datos que guardan cierto tipo de relación específica entre la variable de interés y las variables de información auxiliar.
- Se utilizó la metodología de calibración y se compararon, de forma empírica, para mil iteraciones, las medidas de variabilidad.
Para el primer conjunto de datos, se supuso que existe una relación lineal entre la característica de interés y una variable de información auxiliar continua. Se nota que existe homoscedasticidad en el modelo y que los residuales tienen un comportamiento coherente. A pesar de que ambos estimadores se muestran insesgados para el parámetro de interés, se nota que el estimador de calibración es menos disperso y más eficiente.
Las cuatro siguientes figuras muestran la relación lineal entra las variables (arriba-izquierda), los residuales ajustados en un modelo de regresión simple (arriba-derecha), la dispersión (abajo-izquierda) de las estimaciones de Horvitz-Thompson (puntos grises) y de las estimaciones de calibración (puntos negros), así como la distribución empírica (abajo-derecha) del estimador de Horvitz-Thompson (línea gris) y del estimador de calibración (línea negra), en donde la línea vertical indica el valor del parámetros poblacional.
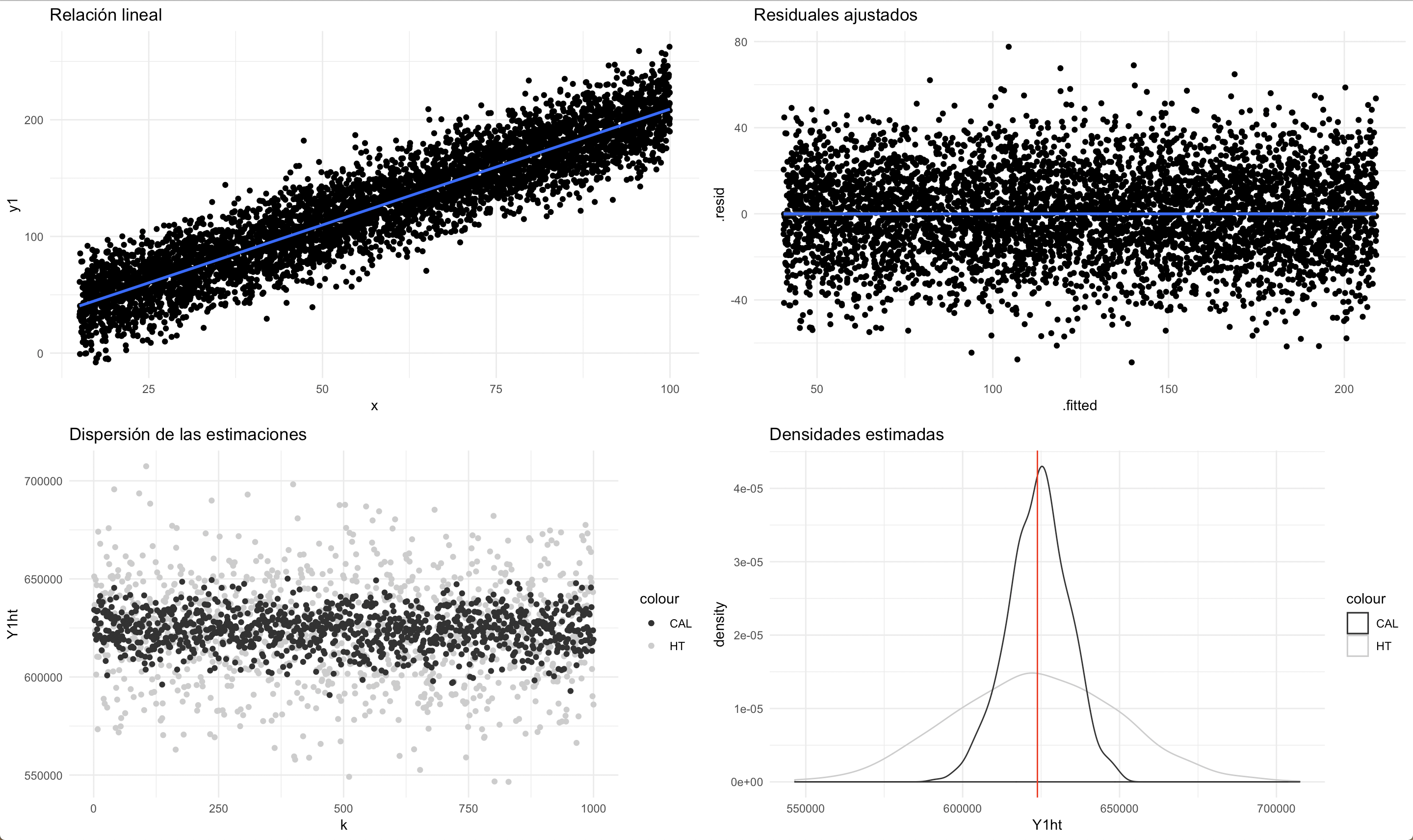
Comportamiento del estimador de calibración en una relación de dependencia lineal
El segundo conjunto de datos asume que existe una relación lineal entre la característica de interés y una variable de información auxiliar continua. Se nota que existe heteroscedasticidad en el modelo y los residuales lo muestran. A pesar de que ambos estimadores se muestran insesgados para el parámetro de interés, el estimador de calibración es un poco más eficiente que el de Horvitz-Thompson.
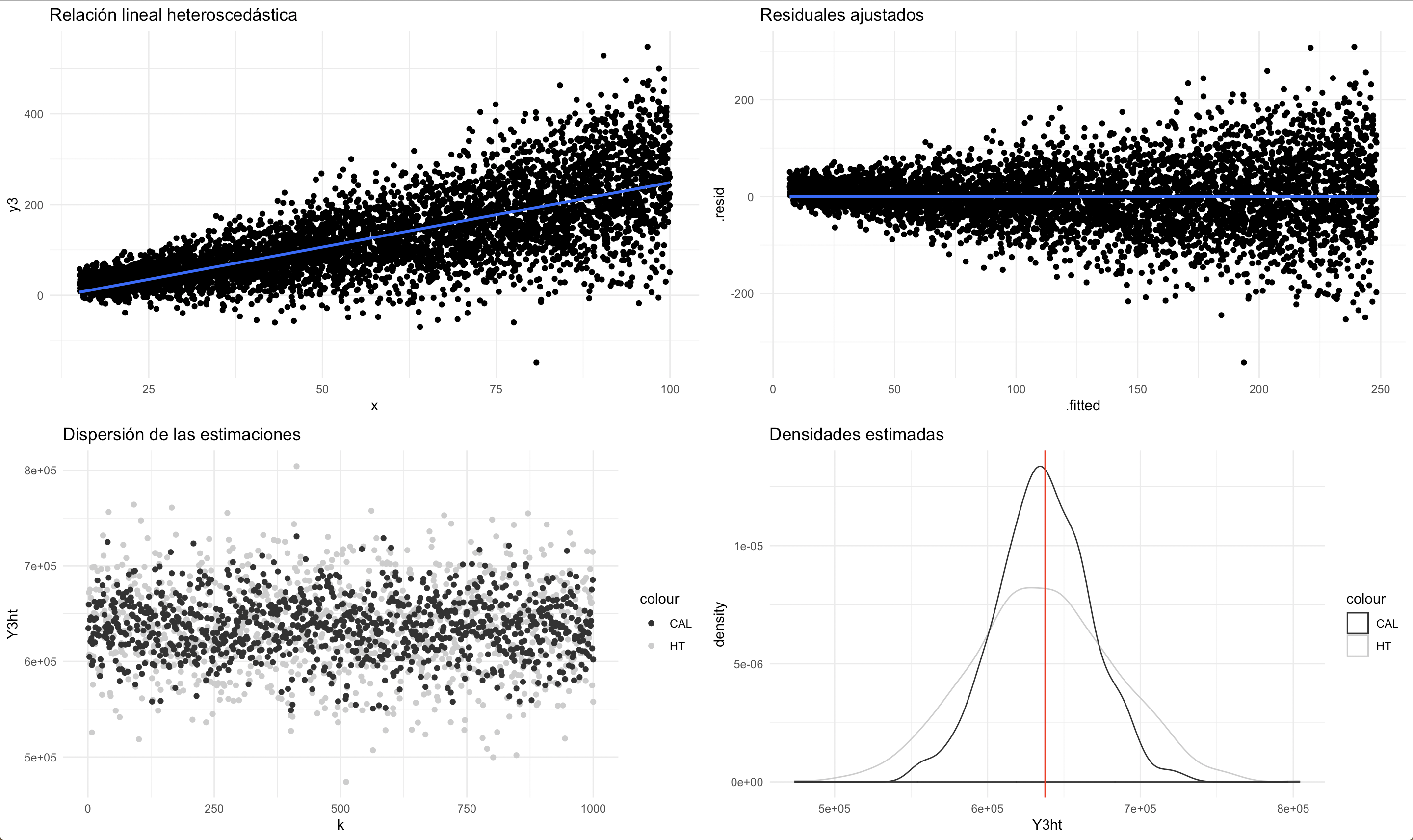
Comportamiento del estimador de calibración en una relación de dependencia lineal con heteroscedasticidad
El tercer conjunto de datos asume que existe una relación cuadrática entre la característica de interés y una variable de información auxiliar continua. Al utilizar un estimador de calibración lineal, los residuales muestran un comportamiento inapropiado. Sin embargo, ambos estimadores se muestran insesgados para el parámetro de interés, pero el estimador de calibración es más eficiente que el de Horvitz-Thompson.
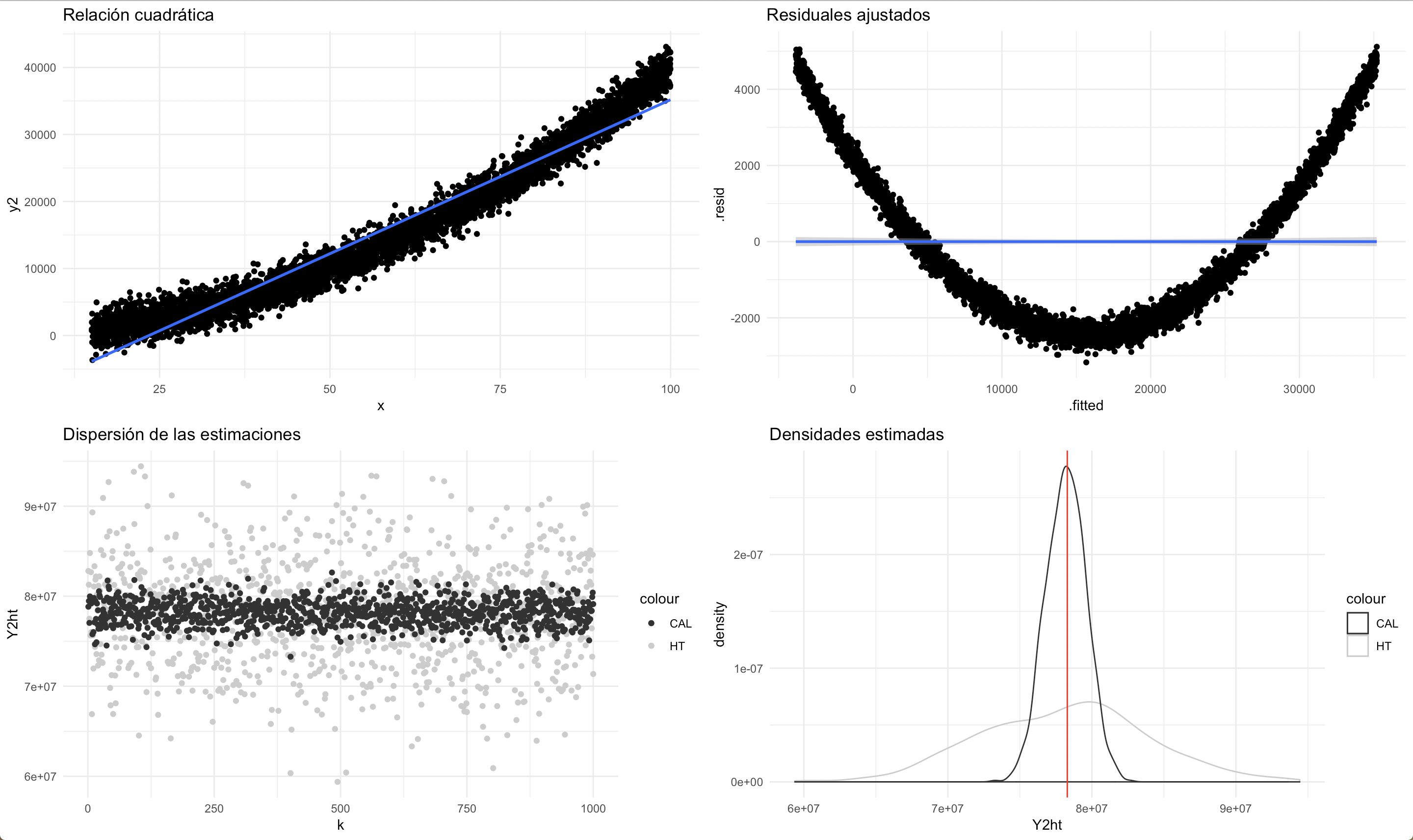
Comportamiento del estimador de calibración en una relación de dependencia cuadrática
El último conjunto de datos asume que existe una relación logística entre la característica de interés y una variable de información auxiliar dicotómica Al utilizar un estimador de calibración lineal, los residuales muestran un comportamiento inapropiado. Ambos estimadores se muestran insesgados para el parámetro de interés e igual de eficientes.
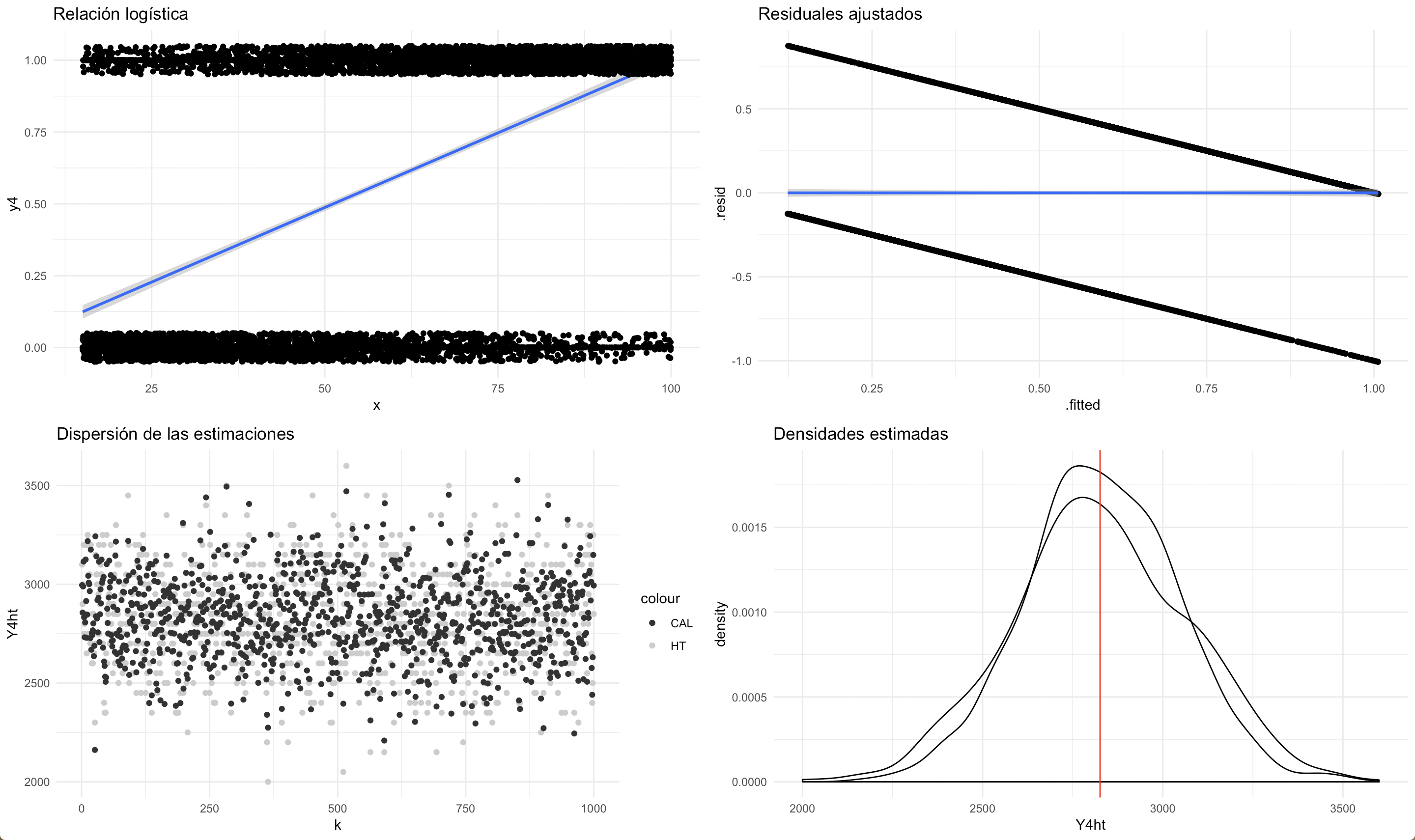
Comportamiento del estimador de calibración en una relación de dependencia logística
Es posible demostrar que la razón entre la varianza del estimador de calibración con la varianza del estimador de Horvitz-Thompson está supeditada al coeficiente de determinación \(R^2_{\xi}\) en un modelo de regresión lineal simple \(\xi\) entre la característica de interés y la información auxiliar.
\[ \frac{Var(\hat t_{y, cal})}{Var(\hat t_{y, HT})} = (1-R^2_{\xi} + o(\sqrt{n})) \approx (1-R^2_{\xi}) \]
Por ende, usar la metodología de calibración supone casi siempre una ganancia en la eficiencia de la estrategia de muestreo.
9.4.2 Diferentes formas del estimador de calibración
La calibración es un ajuste que se realiza a los pesos de muestreo con el propósito de que las estimaciones de algunas variables de control reproduzcan de forma perfecta los totales poblacionales de estas variables. Sin embargo, es necesario tener en cuenta las diferencias entre los métodos de calibración, que en general corresponderán con el nivel de desagregación de información auxiliar:
- Calibración con variables continuas, que es el caso en donde la calibración se realiza con totales de variables continuas como ingreso o gasto, entre otras.
- Post-estratificación con variables categóricas, que representa el caso en donde la calibración se realiza con los tamaños poblacionales (basados en proyecciones demográficas o registros administrativos) de subgrupos de interés.
- Raking con variables categóricas, que se define como una calibración sobre los tamaños marginales de tablas de contingencia de subgrupos de interés. A diferencia del caso anterior, esta calibración no tiene en cuenta los tamaños de los cruces, sino solo los tamaños marginales; por ende, este método induce menos restricciones.
9.4.2.1 Postestratificación
La postestratificación es una de las técnicas más usadas para el ajuste de los pesos de muestreo vía calibración. Este ajuste requiere la definición de categorías poblacionales. Por ejemplo, personas en un determinado grupo de edad, en cierta región y de cierta etnia o raza. Este método se implementa dentro de cada uno de los cruces inducidos por las covariables de interés (edad, región, etnia o raza). Nótese que, es necesario tener acceso a la información auxiliar a nivel de todos los cruces definidos por los subgrupos. Usualmente corresponden a proyecciones demográficas. En este caso, la suma de los pesos ajustados reproducirán con exactitud los tamaños poblacionales en cada cruce.
Las categorías formadas para definir los pesos de muestreo se conocen como post-estratos puesto que son definidas después de que la muestra es seleccionada y los datos son recolectados. Esta es una ventaja pues estas variables no necesariamente participan en la planificación del diseño de muestreo. Por ejemplo, en una encuesta de hogares es difícil estratificar por etnia o raza, edad, sexo o ciclo educativo alcanzado. Como se conoce que estas variables pueden estar correlacionadas con la pobreza, el ingreso o la ocupación, sería una buena idea contemplarlas en la calibración. Suponiendo que se definen cuatro categorías para la raza, dos para sexo, cinco para la edad, entonces habrían 40 post-estratos y sus respectivas restricciones.
De esta manera, siendo \(g = 1, \ldots, G\) el indicador del cruce poblacional (post-estrato), el estimador de postestratifiación queda definido de la siguiente manera:
\[ \hat{t}_{y, pos} = \sum_{g = 1}^G \frac{N_g}{\hat{N}_g}\hat{t}_{y_g} \]
En donde \(N_g\) corresponde al tamaño poblacional del post-estrato, \(\hat{N}_g = \sum_{s_g} d_{k}\) y \(\hat{t}_{y_g} = \sum_{s_g} d_{k} y_k\). Por lo anterior, el factor de expansión de estimador postestratificado queda definido como sigue:
\[ w_k= d_k \frac{N_g}{\hat{N}_g} \ \ \ \ \ (k \in s_g) \]
Note que \(d_k\) corresponde al peso inducido por el diseño de muestreo, corregido por los ajustes de elegibilidad y por la ausencia de respuesta, los cuales serán presentados en los capítulos posteriores del documento.
Por último, se debe considerar que la cantidad de postestratos en la calibración está inducido por la cantidad de interacciones en las variables auxiliares. En algunos casos, es posible encontrar cientos de interacciones. Aunque los tamaños de los postestratos se reproduce sin error, esto puede disminuir la eficiencia de la calibración en las variables de interés. Es decir, muchas variables e interacciones hacen que las estimaciones sean inestables, sobre todo si existen cruces con celdas vacías. Es posible que el efecto de las interacciones influencie la creación de los nuevos pesos calibrados y se tengan datos atípicos en los pesos de calibración resultantes.
9.4.2.2 Raking
¿Qué sucede si los conteos poblacionales (información auxiliar) no están disponibles para todos los cruces de las variables de calibración? Es posible que los agregados poblacionales de las variables provengan de distintas fuentes y no se pueda llegar a nivel de cruce. En este caso, es factible calibrar los marginales de la tabla cruzada, sin necesidad de calibrar todas sus entradas. En este caso, el número de restricciones decrecería con respecto a la postestratifación, pues se sumaría el número de categorías, mientras que en la postestratificación se multiplican. En el escenario anterior, en donde asumimos cuatro categorías para la raza, dos para sexo, cinco para la edad, entonces habrían únicamente 11 restricciones.
Para ajustar los marginales de la tabla cruzada, es necesario realizar un procedimiento iterativo (IPFP), el cual no tiene una escritura cerrada (H. A. Gutiérrez 2016, cap. 10). Por ejemplo, si el raking es de dos marginales, se ajustan primero las filas, luego las columnas y así sucesivamente hasta alcanzar la convergencia de los pesos calibrados y el procedimiento se detiene cuando se alcanza una tolerancia prefijada. Sin pérdida de generalidad, bajo este enfoque, los pesos calibrados se escriben de la siguiente manera:
\[w_k = d_k \times exp(u_h) \times exp(v_g)\]
En donde \(u_h\) es una función de los totales marginales de las filas de la tabla cruzada y \(v_g\) es una función de los totales marginales de las columnas. El raking permite utilizar variables que pueden ser predictoras de las variables de interés o explicar la probabilidad de responder del hogar (o persona), además de paliar los efectos nocivos que las bajas tasas de cobertura del marco de muestreo conllevan sobre la inferencia.
9.4.3 La calibración como un cambio de paradigma en una teoría de estimación exhaustiva
C.-E. Särndal (2007) concluye que existen algunas ideas sobre las cuales vale la pena profundizar un poco más. A continuación se reproducen las ideas de H. A. Gutiérrez (2016) sobre estos criterios para enfatizar el uso práctico de los estimadores de calibración:
- La calibración no se puede separar de la práctica. El uso de los métodos de ponderación de las ONE es una costumbre que tiene sus orígenes en la ponderación de unidades mediante el inverso de su probabilidad de inclusión y continuó con las ponderaciones surgidas del enfoque de post-estratificación. Las ponderaciones de calibración extienden las anteriores ideas. Aunque la calibración aparece recientemente en la literatura, no lo es como técnica para producir ponderaciones.
- La calibración no puede separarse de la consistencia estética10. Las ecuaciones de calibración imponen esta propiedad de consistencia sobre el vector de ponderaciones; así que, cuando éste se aplica a las variables auxiliares el resultado será consistente con los totales de estas variables. El deseo de promover la credibilidad en las estadísticas oficiales es una razón para que las entidades busquen este tipo de consistencia.
- La calibración debe ser de fácil interpretación. El enfoque de calibración ha ganado popularidad en las aplicaciones reales debido a que las estimaciones resultantes son fáciles de interpretar y de motivar puesto que están directamente relacionadas a los pesos inducidos por el diseño de muestreo. La calibración sobre los totales conocidos brinda al usuario una forma natural y transparente de estimación. El usuario que entiende la ponderación muestral aprecia el método de calibración puesto que modifica sutilmente los pesos originales, pero al mismo tiempo respeta los totales de la información auxiliar. Además, la calibración induce un único vector de ponderaciones aplicable a todas las variables involucradas en el estudio. Esta última razón hace que este método sea muy apetecido en las entidades oficiales que manejan encuestas muy extensas.
- La calibración representa un enfoque exhaustivo y unificado basado en los avances de teorías anteriores. En la práctica de las enceustas de hogares, es cpmún encontrar problemas como la ausencia de respuesta, deficiencias del marco muestral y errores de medición. Aunque algunos procesos como la imputación y la reponderación son ampliamente difundidos y usados en la práctica, estos métodos no están necesariamente enmarcados dentro de una teoría exhaustiva de inferencia en poblaciones finitas. La mayoría de artículos teóricos tratan con la estimación de parámetros bajo un mundo ideal, que no existe en la práctica, donde la ausencia de respuesta y otros errores no muestrales están ausentes. La calibración proporciona una teoría unificada que hace frente a estos inconvenientes.
Referencias
En este apartado la palabra consistente se da en el sentido de que el estimador reproduce exactamente los totales de la información auxiliar.↩︎