15.2 Ejemplo: detección de valores atípicos en una encuesta de presupeustos familiares y gastos
En genral, para cualquier tipo de encuesta, a la hora de detectar valores atípicos podría considerarse la estructura multivariante de los datos (relación con otras variables) en la búsqueda de valores atípicos. Para esto se debería elegir un conjunto de covariables de acuerdo con el juicio de los expertos y la desagregación necesaria. A pesar de que en la base de datos existan registros y valores observados para una observación, es posible que, después de la detección de valores atípicos, toda la información de una unidad sea declarada sospechosa. Por ende, una vez que se ha detectado una unidad con valores atípicos potenciales, es posible decidir que todos sus registros sean eliminados (creando deliberadamente una ausencia de respuesta de unidad) de no comprobarse la fiabilidad de la información. Por consiguiente, si se mantiene la unidad, toda su información se declara como confiable y valdrá la pena analizarla. De lo contrario, el registro se eliminará de los datos de la muestra que afectan la estructura del esquema de ponderación. Luego, la unidad se declarará como una unidad eligibles no respondientes (ENR, ver capitulo 10).
Después de decidir acerca de los valores atípicos de la unidad, es necesario detectar los valores atípicos de los registros para las variables específicas de la encuesta. Por ejemplo, en una encuesta de presupuestos familiares, las variables de interés serán los rubros asociados a los ingresos y a los gastos del hogar. En este caso, se sugiere que la variable de interés de una categoría particular se transforme utilizando el enfoque de Box-Cox. Esto se hace porque las distribuciones de ingresos y gastos siempre están sesgadas. Una vez transformados, es posible utilizar las medidas anteriormente mencionadas para decidir acerca de la eliminación del registro. Por ejemplo, si dos o tres de los métodos detectan un registro como un posible valor atípico, entonces se verifica la información sobre ese registro. Si la información del elemento es sospechosa, se debe eliminar y utilizar un enfoque de imputación sobre ese registro.
Siguiendo con el esquema de la encuesta de presupuestos familiares, podría ser conveniente que, a nivel de gasto, la detección de los valores atípicos se realizara, no sobre cada artículo, sino a nivel agregado para cada nivel de la clasificación de consumo (COICOP, Classification of Individual Consumption According to Purpose). Además se deben tener en cuenta que, en este tipo de encuestas, los valores nulos para el gasto o consumo de artículos particulares son frecuentes, ya que no se puede esperar que todos los hogares consuman todos los artículos posibles. Estos valores cero se denominan ceros estructurales. Por ende, es muy pertinente estudiar y decidir si la metodología de detección de valores atípicos tendrá en cuenta los ceros o no. En general, cuando la incidencia de los ceros es baja no debería existir ningún inconveniente en analizar el conjunto de datos incluyendo estos ceros. Por ende, esta decisión debería ser independiente para cada división.
Para algunos componentes concretos, el número de ceros puede ser bastante alto y los algoritmos de detección de valores atípicos pueden fallar si el número de ceros está por encima de un determinado umbral. Las observaciones podrían incluso convertirse en valores atípicos debido a los ceros cuando se aplican métodos de detección. En este sentido, es necesario contemplar umbrales flexibles para cada división. Por ejemplo, un valor de cero en los gastos de alimentos sería poco realista, pero podría ser cierto para los gastos en ropa de bebé o muebles. Por las anteriores razones, es plausible recomendar la agregación de los componentes del consumo en grandes categorías a nivel de producto/servicio o grupos agregados de productos y servicios.
Un indicador fiable, no solo para medir la desigualdad en el consumo sino también para realizar un seguimiento de los cambios en el proceso de detección de valores atípicos y la imputación posterior, es el coeficiente de Gini. Por ejemplo, considere la siguiente tabla que muestra la presencia de ceros en cada división COICOP junto con el Gini para algunas de las categorías anteriormente mencionadas. Nótese que la incidencia de ceros es mucho menor en la categoría de vivienda que en las categorías de educación o recreación.
| Categoría | Ceros | Gini |
|---|---|---|
| Alimentos | 27 | 36 |
| Alcohol | 4333 | 90 |
| Ropa | 2558 | 78 |
| Vivienda | 5 | 48 |
| Muebles | 85 | 53 |
| Salud | 2746 | 78 |
| Transporte | 616 | 69 |
| TIC | 551 | 62 |
| Recreación | 3538 | 92 |
| Educación | 4802 | 90 |
| Restaurantes | 1421 | 65 |
| Seguros | 4837 | 90 |
| Cuidado personal | 129 | 51 |
Esta metodología también se puede aplicar para grupos. La siguiente tabla muestra la presencia de ceros estructurales para algunos artículos de la sección Alimentos. Una vez más, dependiendo del país, sería esperable encontrar una mayor incidencia de ceros en algunos artículos. En este caso particular, nótese que hay una mayor cantidad de ceros en artículos como té o café, que en artículos como cereal, azúcar o leche.
| Artículos | Ceros | Gini |
|---|---|---|
| Cereales | 87 | 37 |
| Carne | 481 | 47 |
| Pescado | 305 | 56 |
| Leche | 290 | 47 |
| Aceites | 482 | 51 |
| Frutas | 981 | 67 |
| Verduras | 188 | 47 |
| Azucares | 290 | 56 |
| Comida procesada | 253 | 43 |
| Jugos | 3650 | 79 |
| Café | 5286 | 86 |
| Té | 4709 | 86 |
| Cacao | 4421 | 78 |
| Agua | 5287 | 86 |
| Refresco | 4859 | 86 |
| Otras bebidas | 3353 | 79 |
Como se resaltó anteriormente, para datos muy sesgados, los métodos para la detección de valores atípicos podrían resultar problemáticos, ya que el intervalo en el que los puntos de datos no se consideran valores atípicos es simétrico alrededor de la mediana. Por ejemplo, la figura 15.1 muestra el comportamiento estructural de algunas divisiones, es notable que todas las distribuciones de gasto y consumo en estos conceptos están extremadamente sesgadas.
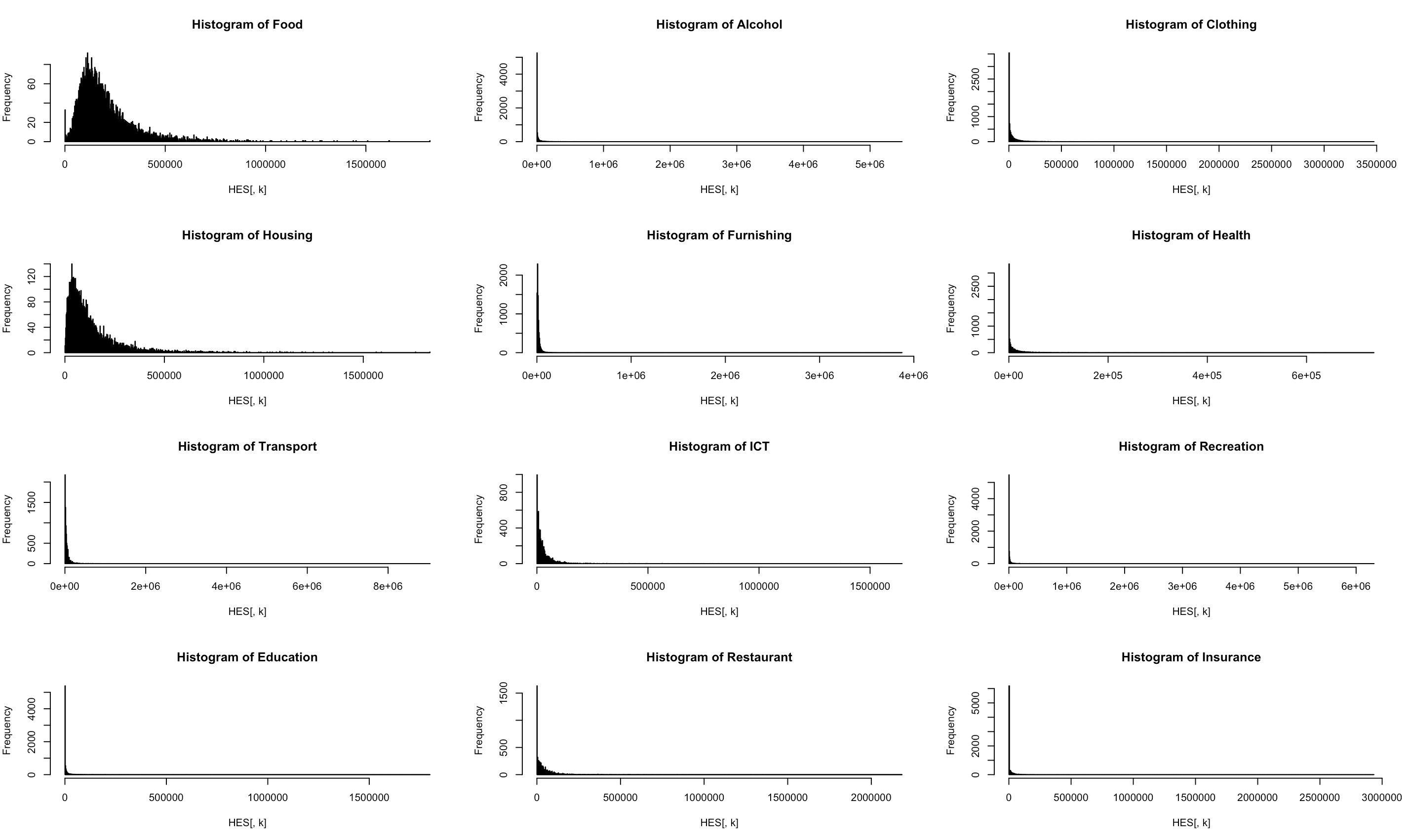
Figura 15.1: Distribución del consumo para algunas categorías del gasto.
Para ajustarse a este problema es posible utilizar la transformación de Box-Cox con el fin de obtener una distribución simétrica para los datos antes de determinar los posibles valores atípicos. La figura 15.2 muestra el proceso de iteración de esta metodología en algunas divisiones. La línea vertical en cada gráfica corresponde al mejor valor que podría tomar \(\lambda\) para que los datos se ajusta a una distribución normal.
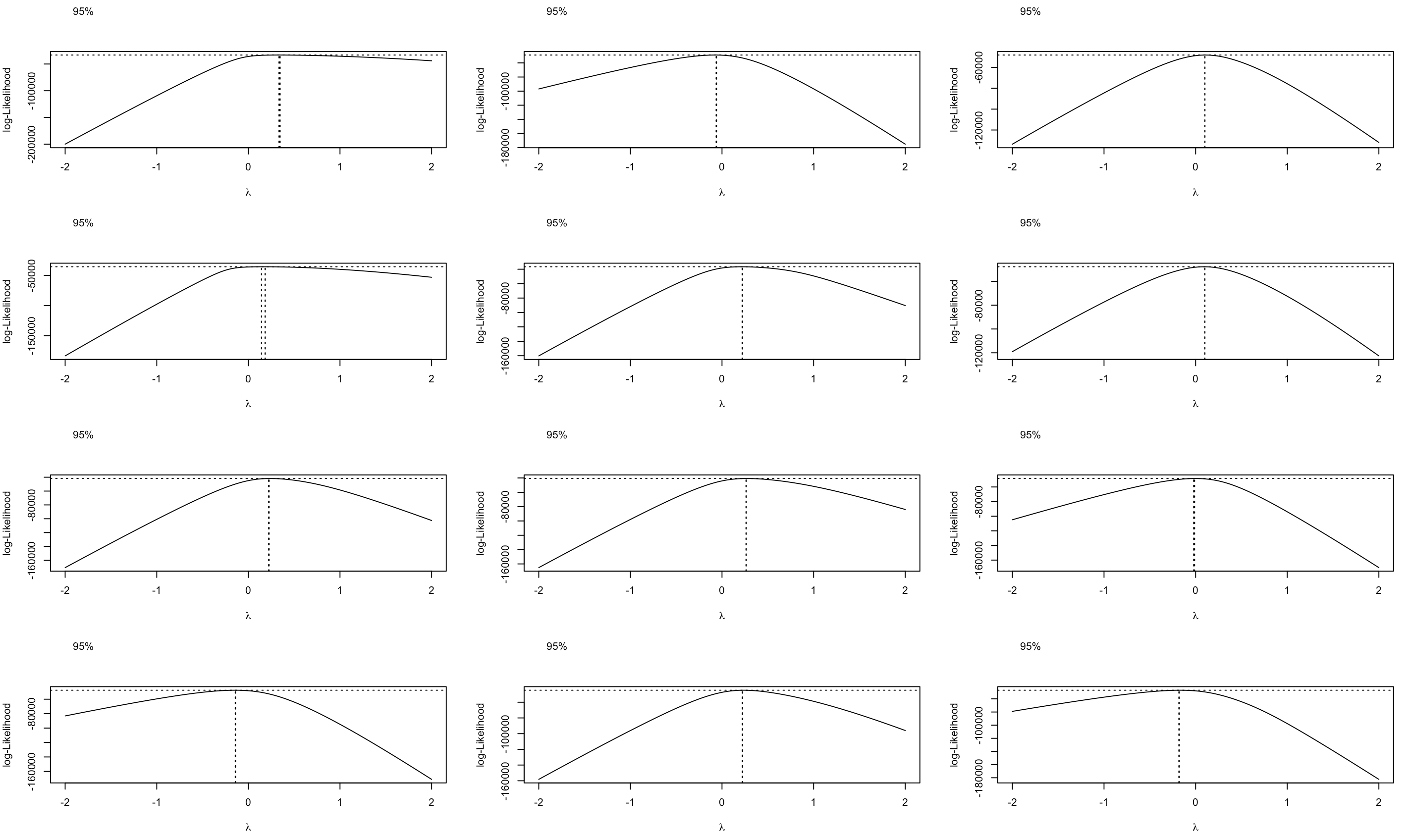
Figura 15.2: Valores óptimos para las transformaciones de Box-Cox en algunas categorías del gasto.
Luego de haber transformado apropiadamente los datos, es posible utilizar la metodología de Boxplot, uno de los métodos más básicos (aunque muy poderoso), para identificar valores atípicos. Como se mencionó en la sección anterior, la gráfica mostrará el mínimo de la muestra, el primer cuartil, la mediana, el tercer cuartil y el máximo. La caja va del primer al tercer cuartil (que contiene por definición el 50% de los datos más internos), así como la mediana que generalmente está marcada por una línea media. Para la aplicación específica de la detección de valores atípicos dentro de las divisiones COICOP es posible que la constante predeterminada \(c\) varíe entre divisiones. Por ejemplo, la siguiente tabla muestra el número de valores atípicos detectados en cada división por este método.
| División | Valores atípicos |
|---|---|
| Alimentos | 222 |
| Alcohol | 0 |
| Ropa | 0 |
| Vivienda | 87 |
| Muebles | 330 |
| Salud | 0 |
| Transporte | 743 |
| TIC | 668 |
| Recreación | 0 |
| Educación | 0 |
| Restaurantes | 31 |
| Seguros | 0 |
| Cuidado personal | 400 |
Por otro lado, también es posible tener en cuenta la relación entre el gasto en cada división y el ingreso reportado por el hogar en la encuesta. En general, no se puede suponer que esta relación es homogénea entre todos los encuestados, máxime si se tiene en cuenta que la selección de las unidades muestrales se hace en todos los grupos socioeconómicos del país. Sin embargo, sí es posible hacer este supuesto dentro de clases homogéneas, como por ejemplo el cruce entre los quintiles (o deciles) del ingreso y las regiones del país. De esta forma, dentro de cada grupo se supondría que la relación entre el gasto y el ingreso es uniforme. Por ejemplo, en la siguiente tabla se muestra el número de valores atípicos detectados en cada división mediante el método Hidiroglou-Bertholot.
| División | Valores atípicos |
|---|---|
| Alimentos | 74 |
| Alcohol | 141 |
| Ropa | 73 |
| Vivienda | 53 |
| Muebles | 177 |
| Salud | 71 |
| Transporte | 89 |
| TIC | 128 |
| Recreación | 168 |
| Educación | 117 |
| Restaurantes | 48 |
| Seguros | 100 |
| Cuidado personal | 247 |
Es necesario tener en cuenta que, como la lógica detrás de estos dos métodos difiere, cada uno identificará un número diferente de valores atípicos. Esto es una ventaja, porque los métodos son complementarios. Por ejemplo, en divisiones como ropa, vivienda, salud, recreación y educación, donde el método Boxplot no encontró ningún valor atípico posible, el método HB sí lo encontró. Es así como, teniendo en cuenta los resultados de estos dos métodos, se puede especificar una regla lógica para asignar una marca a los registros de la base de datos que deban ser revisados por considerarse sospechosos. Por ejemplo, es posible que haya categorías en las que la regla lógica sea una conjunción de los resultados de los métodos, mientras que podría haber otras en las que la regla lógica sea una disyunción entre los resultados.
Al final, se debe imputar cualquier valor que se considere como un valor atípico. Como se vio en los capítulos anteriores, la imputación puede estar apoyada por un enfoque basado en modelos. Por ejemplo, para imputar el gasto percápita anualizado, es posible utilizar el método de regresión con el vecino más cercano, donde se define un modelo lineal para las unidades encuestadas (sin incluir los valores atípicos). Una vez estimados los coeficientes de regresión, se calcula un valor previsto para esas unidades de valores atípicos y se identifica a un solo donante como el hogar cuyo gasto total en esa División está más cerca de la predicción. En la siguiente tabla se presentan algunos resúmenes de la distribución de los gastos a nivel de división antes de imputar los valores atípicos.
| División | Mínimo | Mediana | Máximo |
|---|---|---|---|
| Alimentos | 0 | 164587 | 1819370 |
| Alcohol | 0 | 0 | 5475960 |
| Ropa | 0 | 8180 | 3474000 |
| Vivienda | 0 | 89040 | 1835500 |
| Muebles | 0 | 10503 | 3871476 |
| Salud | 0 | 2400 | 735180 |
| Transporte | 0 | 24700 | 9038783 |
| TIC | 0 | 16125 | 1642500 |
| Recreación | 0 | 860 | 6307200 |
| Educación | 0 | 0 | 1800000 |
| Restaurante | 0 | 22100 | 2184000 |
| Seguro | 0 | 0 | 2932400 |
| Cuidado personal | 0 | 18540 | 1223734 |
Por último, en la tabla que se muestra a continuación se examinan algunos resúmenes sobre la distribución de los gastos a nivel de división habiendo imputado los valores atípicos de forma diferencial y con independencia ne cada división. Se nota cómo la imputación pasa realmente cambia la perspectiva del consumo mínimo y máximo. Esto significa que la detección de valores atípicos se centró en ambos lados de la distribución del gasto.
| División | Mínimo | Mediana | Máximo |
|---|---|---|---|
| Alimentos | 4560 | 166280 | 1616504 |
| Alcohol | 0 | 0 | 930400 |
| Ropa | 0 | 8250 | 1446532 |
| Vivienda | 3000 | 89280 | 726000 |
| Muebles | 243 | 10730 | 279382 |
| Salud | 0 | 2400 | 654000 |
| Transporte | 60 | 29900 | 365000 |
| TIC | 0 | 16627 | 591000 |
| Recreación | 0 | 867 | 1054100 |
| Educación | 0 | 0 | 494000 |
| Restaurantes | 0 | 22133 | 520000 |
| Seguro | 0 | 0 | 723000 |
| Cuidado personal | 400 | 18855 | 658960 |